Webスクレイピングで営業リストを作成する(1)
あるサイトから、企業・店舗などの情報を収集して、営業リストを作成します。一般にWebスクレイピングと呼ばれる方法です。
実際の個人や企業データを表示するのは問題があるので、ケーススタディとして、全国の裁判所情報を収集することにします。
各地の裁判所の所在地・電話番号等一覧
作業手順
- サイト利用規約の確認
- 操作手順、取得項目の確定
- XPath取得
- スクリプト作成
- デバッグ、エラー対応
- データ補正、スクリプトの改良
- 評価、考察
利用規約の確認
対象となるサイトが
- スクレイピング(ロボットによる自動取得)禁止でないこと
- 情報の転用を禁止していないこと
を確認します。
Webスクレイピングを禁止していない場合でも、あまりに高速かつ集中的に大量データを収集すると、サーバーに負荷がかかり、相手方に迷惑がかかります。サーバーの過負荷で、サービスの遅延や停止が発生すると、最悪の場合、訴えられないとも限りませんので、常識的な範囲で利用するようにします。(人間の速度の数倍程度なら問題ないでしょう)
規約の確認
スクレイピングやクローラーによる自動取得を禁止していません。
掲載情報についても、著作権の範囲内で利用とのことです。
操作手順、取得項目
リンクをたどっていくと次のようになります。
A.全国の裁判所一覧 ⇒ B.地域の裁判所一覧 ⇒ C.住所・電話番号
A.全国画面

操作内容
各欄のリンク「所在地・代表電話」をクリックします。
B.地域画面

操作内容
各欄の左側のリンクをクリックします。
C.詳細画面

操作内容(取得項目)
裁判所名、郵便番号、所在地、電話番号を取得します。
上記の例では郵便番号が3個、所在地にアクセス方法が含まれていますが、いったんこのままで取得します。
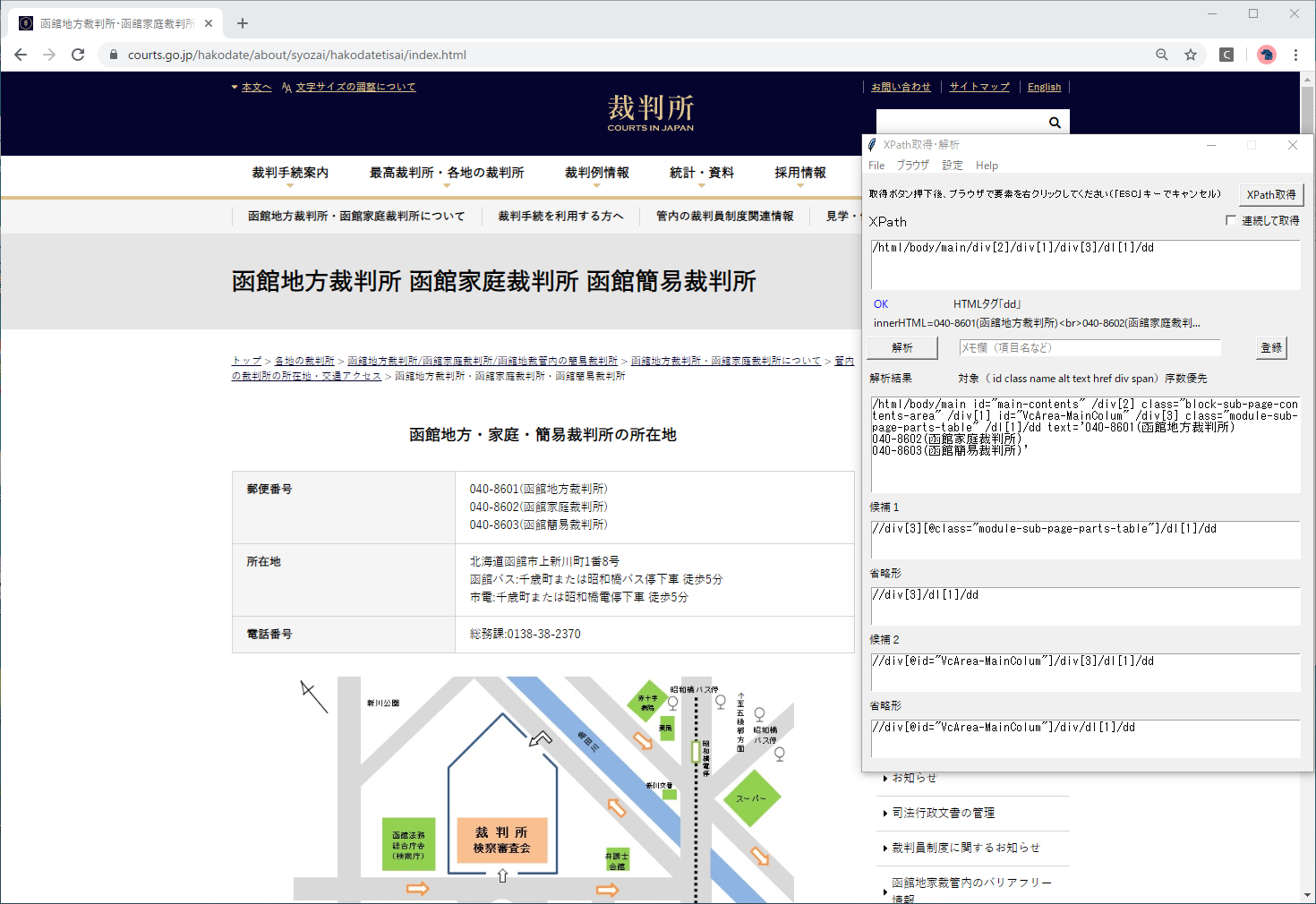
XPath取得
各画面のXPathをXPath取得ツールで取得します。
A.全国画面
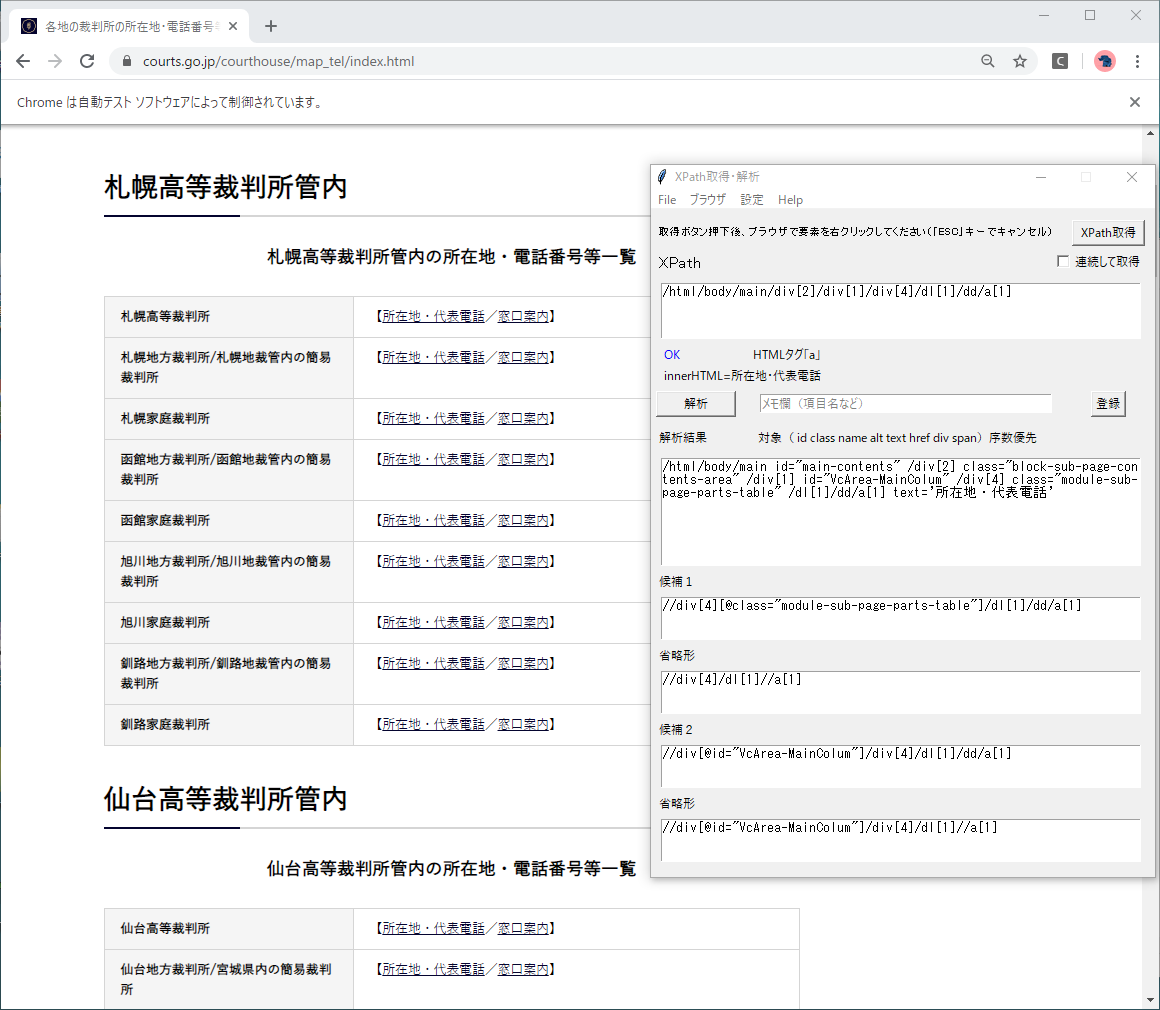
取得されたXPath
| 札幌高等裁判所管内 | ||
|---|---|---|
| 札幌高等裁判所 | 所在地・代表電話 | //div[4]/dl[1]//a[1] |
| 札幌地方裁判所/札幌地裁管内の簡易裁判所 | 所在地・代表電話 | //div[4]/dl[2]//a[1] |
| 札幌家庭裁判所 | 所在地・代表電話 | //div[4]/dl[3]//a[1] |
| 函館地方裁判所/函館地裁管内の簡易裁判所 | 所在地・代表電話 | //div[4]/dl[4]//a[1] |
| 函館家庭裁判所 | 所在地・代表電話 | //div[4]/dl[5]//a[1] |
| 旭川地方裁判所/旭川地裁管内の簡易裁判所 | 所在地・代表電話 | //div[4]/dl[6]//a[1] |
| 旭川家庭裁判所 | 所在地・代表電話 | //div[4]/dl[7]//a[1] |
| 釧路地方裁判所/釧路地裁管内の簡易裁判所 | 所在地・代表電話 | //div[4]/dl[8]//a[1] |
| 釧路家庭裁判所 | 所在地・代表電話 | //div[4]/dl[9]//a[1] |
| 仙台高等裁判所管内 | ||
| 仙台高等裁判所 | 所在地・代表電話 | //div[7]/dl[1]//a[1] |
| 仙台地方裁判所/宮城県内の簡易裁判所 | 所在地・代表電話 | //div[7]/dl[2]//a[1] |
表は、TABLEタグではなく、divとdlタグで記述されているようです。
そして各表は、札幌div[4]、仙台div[7]、東京div[10]のように、3つ飛ばしで記述されています。
しかし、これですとプログラムで扱う時に、表ごとの変数(dvの序数)と、各裁判所ごとの変数(dlの序数)が必要になり、不便です。そもそも、出力リストは高等裁判所の管区ごとに分ける必要はありません。
ということで、表構造を無視して、リンクだけを指定するようにします。リンクの文言は「所在地・電話番号」で統一されていますので、<a>タグの文言が「所在地・電話番号」である要素を指定すればよいことになります。
XPathでテキストを指定する記述方法
試しに、左端の裁判所名のXPathを取得してみます。

XPathは //dt[contains(text(),'札幌高等裁判所')] となりました。
このことから、リンク要素のXPathは //a[contains(text(),’所在地・代表電話’)] となることが分かります。
XPathの検証
実際に上記のXPathでリンク要素を取得できるかを、XPath検証ツールでチェックします。
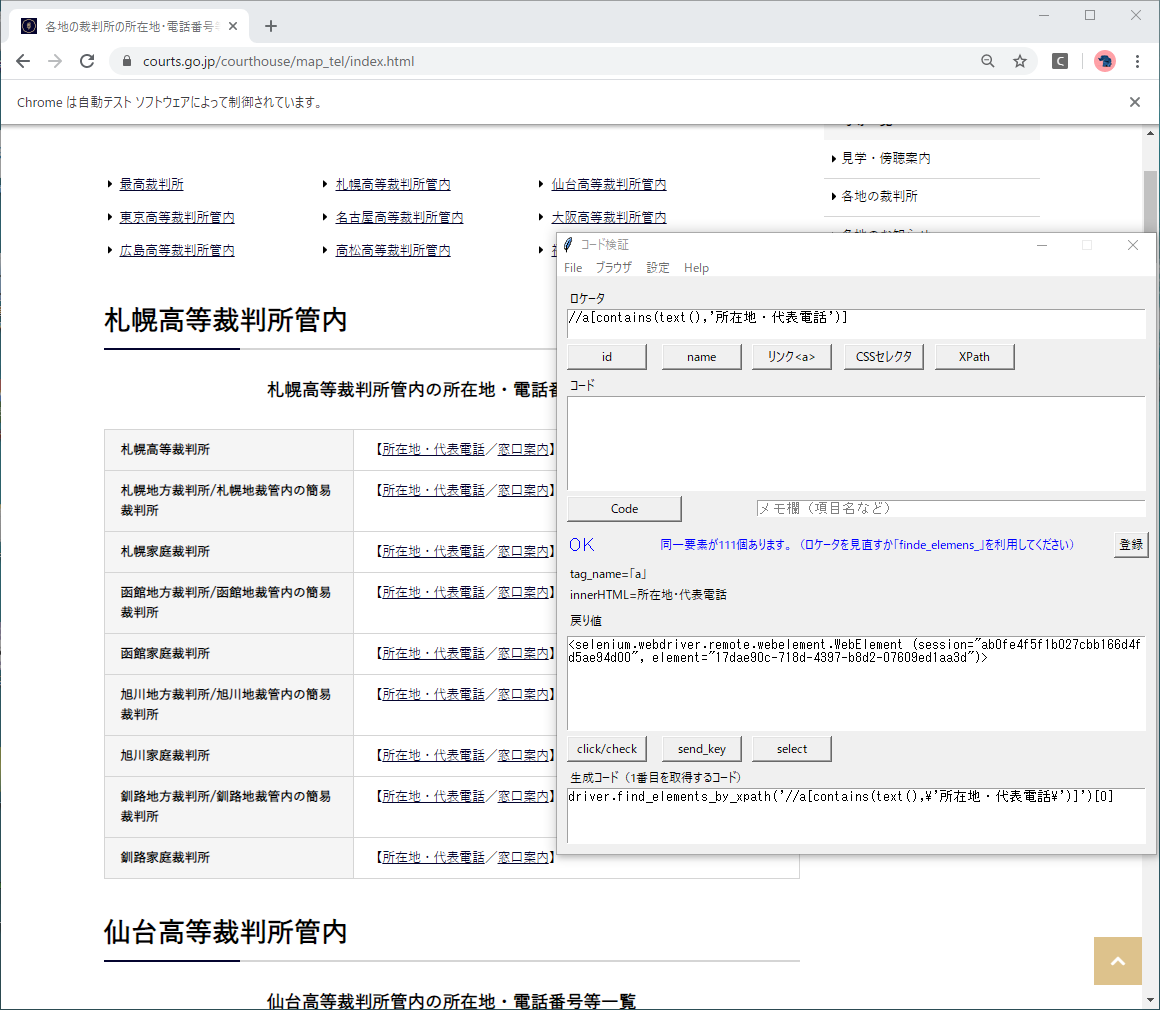
【同一要素が111個あります】と表示されました。
文言が「所在地・代表電話」の<a>タグを一律に取得するので、重複が発生していますが、動作としては正常です。しかし実際のシナリオでは、その中から1個を特定して操作することになります。
生成コード欄にdriver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]')[0]
とありますように、スクリプトを作成する時は、使用するメソッドを[find_elements]にした上で、末尾に序数を付けて操作します。
なお、内側の「’(シングルクォーテーション)」はエスケープ処理「\(円マーク)」が必要です。
補足
今回は要素をXPathで取得していますが、Seleniumにはリンクの文言で要素を指定する方法もあります。
XPath検証ツールで、リンク文言(所在地・代表電話)を入力してボタンを押せば、要素を取得するコードが出力されます。
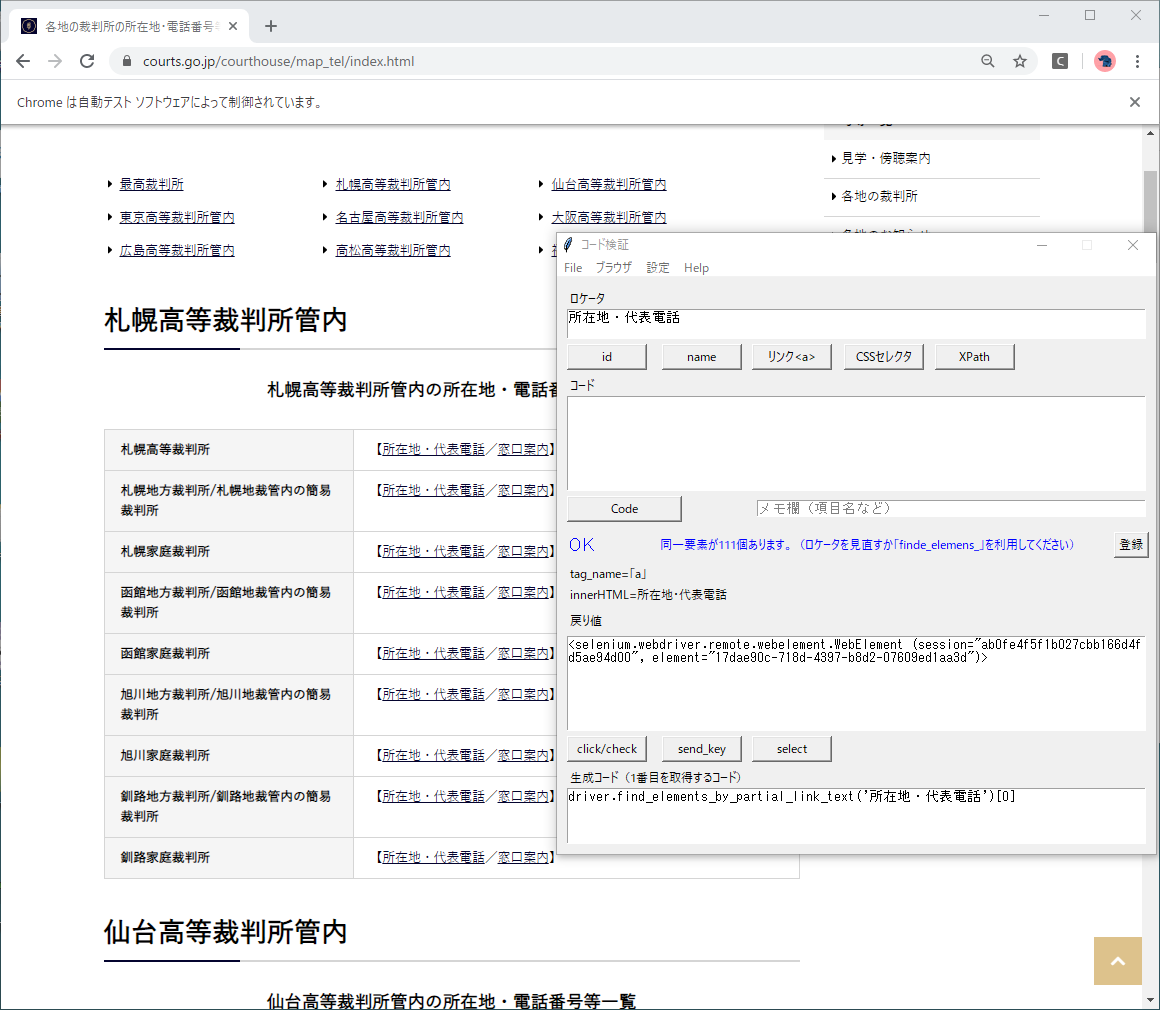
やはり要素が111個取得され、生成コードはdriver.find_elements_by_partial_link_text('所在地・代表電話')[0]
となります。
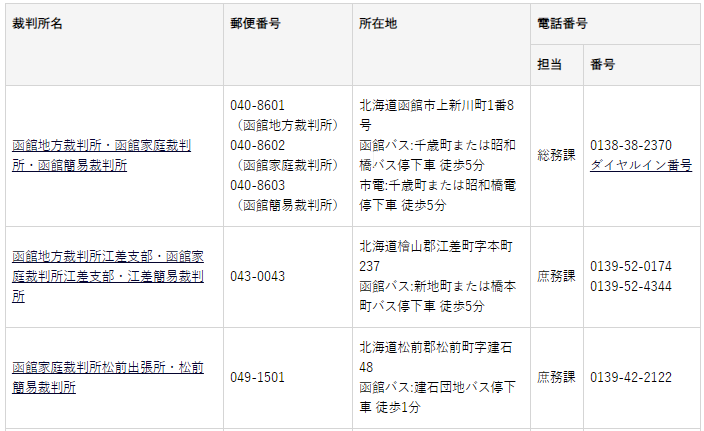
B.地域画面
XPath取得
XPath取得ツールでXPathを取得します。

| 裁判所名 | XPath |
|---|---|
| 函館地方裁判所・函館家庭裁判所・函館簡易裁判所 | //div//tr[3]/td[1]/a |
| 函館地方裁判所江差支部・函館家庭裁判所江差支部・江差簡易裁判所 | //div//tr[4]//a |
| 函館家庭裁判所松前出張所・松前簡易裁判所 | //div//tr[5]//a |
| 函館家庭裁判所八雲出張所・八雲簡易裁判所 | //div//tr[6]//a |
| 函館家庭裁判所寿都出張所・寿都簡易裁判所 | //div//tr[7]//a |
一番上だけが、tdタグを省略できていないのが気になります。

表の同じ行に、もうひとつ<a>タグ(ダイヤルイン番号)があるのが原因です。
tdタグを省略してしまうと、住所のリンクと、ダイヤルインのリンクを区別できなくなります。ダイヤルインが表示されるケースは他にもあるでしょうから、tdは省略できません。
よって、XPathは
//div//tr[序数]/td[1]/a
となり、序数は3始まりで、1ずつ加算することになります。
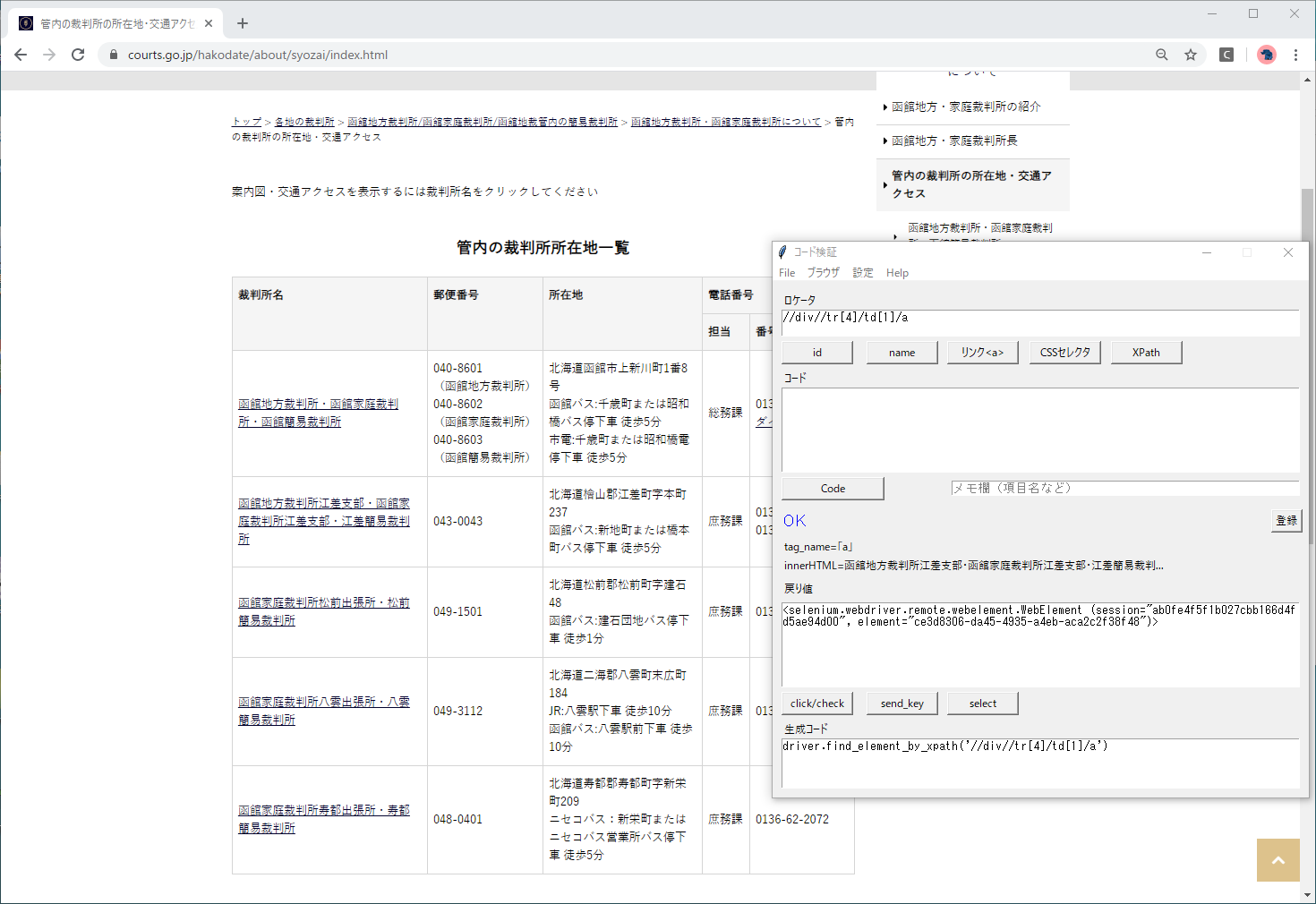
XPath検証
念のため、tdを付け加えて要素が取得できることを、XPath検証ツールで確認します。
C.詳細画面
XPath取得
XPath取得ツールでXPathを取得します。
| 項目 | XPath |
|---|---|
| 裁判所名 | //div[@id="VcArea-MainColum"]/div/h3 |
| 郵便番号 | //div[@id="VcArea-MainColum"]/div/dl[1]/dd |
| 所在地 | //div[@id="VcArea-MainColum"]/div/dl[2]/dd |
| 電話番号 | //div[@id="VcArea-MainColum"]/div/dl[3]/dd |
使用するXPath
| 画面 | 項目 | XPath | 操作 | 序数 |
|---|---|---|---|---|
| 全国 | リンク | //a[contains(text(),’所在地・代表電話’)][序数] | クリック | 0始まり |
| 地域 | リンク | //div//tr[序数]/td[1]/a | クリック | 3始まり |
| 詳細 | 名称 | //div[@id="VcArea-MainColum"]/div/h3 | テキスト取得 | |
| 〒 | //div[@id="VcArea-MainColum"]/div/dl[1]/dd | テキスト取得 | ||
| 住所 | //div[@id="VcArea-MainColum"]/div/dl[2]/dd | テキスト取得 | ||
| TEL | //div[@id="VcArea-MainColum"]/div/dl[3]/dd | テキスト取得 |
操作コード
上記のXPathから要素を操作するコードを確定します。
| 画面 | 項目 | 操作コード | 変数 |
|---|---|---|---|
| 全国 | リンク | driver.find_elements_by_xpath(('//a[contains(text(),\'所在地・代表電話\')]')[i].click() |
0始まり |
| 地域 | リンク | driver.find_element_by_xpath('//div//tr[j]/td[1]/a').click() |
3始まり |
| 詳細 | 名称 | driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/h3').text |
|
| 〒 | driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text |
||
| 住所 | driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text |
||
| TEL | driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text |
全国画面では、「所在地・代表電話」の<a>タグ(111個)を取得し、0番目から順番にクリックします。
よって、find_elementsで複数要素を取得し、取得した要素を順番に処理します。
一方、地域画面では、//div//tr[j]/td[1]/aでXPathを指定します。この場合、取得される要素はj番目の1個だけです。よってfind_elementで1個の要素を取得・操作します。
4.Seleniumスクリプト作成
実行環境の準備
- Python実行環境を準備します。
Pythonのインストール - Seleniumの 実行環境を準備します。
Seleniumのインストール - Excelを操作するためのPythonライブラリを導入します。
xlwingsのインストール - 使用するブラウザのドライバを導入します。
Google Chrome
Firefox
Microsoft Edge
Internet Explorer
スクリプト構成
Seleniumスクリプトのプログラム構成(フローチャート)を考えます。
- 利用するライブラリを使う準備(import)
- ブラウザを操作するWebドライバの起動
- 出力Excelシートを開く
- ブラウザ操作
- 全国の裁判所一覧ページに移動
- 地域一覧ページに遷移
- 詳細画面に遷移
- 出力項目をExcelに出力
- Excelシートの保存
1~3はブラウザ操作を行うための前準備、5は後処理ですので、1回だけ実行します。
4は画面操作なので、裁判所の件数分、繰り返しの処理となります。
1.ライブラリのインポート
Pythonライブラリ(モジュール)を使用するために、前もって使用するライブラリを import文で読み込みます。
#Seleniumライブラリ
from selenium import webdriver#Excel操作ライブラリ
import xlwings as xw2.Webドライバの起動
操作するブラウザのWebドライバを起動します。
#Chrome
driver_path = (Webドライバの配置先)
driver = webdriver.Chrome(executable_path=driver_path)#Firefox
driver_path = (Webドライバの配置先)
driver = webdriver.Firefox(executable_path=driver_path)#Microsoft Edge
driver_path = (Webドライバの配置先)
driver = webdriver.Edge(executable_path=driver_path)#Intenet Explorer
driver_path = (Webドライバの配置先)
driver = webdriver.Ie(executable_path=driver_path)3.Excelシートを開く
Excelブックを開き、シートの1行目にヘッダ情報を出力します。
# Excelオープン
book_path = (Excelブックの配置先)
wb1 = xw.Book(book_path)
ws1 = wb1.sheets[0] #シート1枚目
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'5.Excelシートの保存
Excelブックを保存して閉じます。
#Excel保存
wb1.save(book_path)
wb1.close()4.ブラウザ操作
- 全国の裁判所一覧ページに移動
- 地域一覧ページに遷移
- 詳細画面に遷移
- 項目をExcelに出力
4-1.全国の裁判所一覧ページに移動
ブラウザに「所在地一覧」のURL(https://www.courts.go.jp/courthouse/map_tel/index.html)を入力します。
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')4-2.地域一覧ページに遷移

【所在地・代表電話】をクリックします。
driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]')[i].click()変数「i」は0始まりで、1ずつ加算されます。
4-3.詳細画面に遷移
各裁判所へのリンクをクリックします。
driver.find_element_by_xpath('//div//tr[j]/td[1]/a').click()このままですと、「j」は変数ではなく「j」という固定文字として、解釈されますので
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a').click()のように、シングルクォーテーションの外に出します。
変数「j」は3始まりで1ずつ加算されます。
4-4.項目をExcelに出力
名称、郵便番号、所在地、電話番号をExcelのk行目に出力します。
#Excel出力
ws1.cells(k, 1).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/h3').text
ws1.cells(k, 2).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').textExcelシートの1行目がヘッダーなので、変数「k」は2始まりで、1ずつ加算されます。
ブラウザ操作の繰り返し
これらの操作をループで繰り返します。操作内容は
- 全国一覧画面で「所在地・代表電話」のリンクをクリックして、地域一覧画面に遷移
変数:i、0始まり、1ずつ加算 - 地域一覧画面で各裁判所のリンクをクリックして詳細画面に遷移
変数:j、3始まり、1ずつ加算 - 詳細画面の内容をExcelに記載
変数:k、2始まり、1ずつ加算
でした。
これらのことから、全国のi件目について、地域をj件処理することになります。
そしてkは、i,jと関係なくシートに記載するたびに1ずつ増やします。
| 全国 | 地域 | 裁判所 | i(全国) | j(地域) | k(Excel) |
|---|---|---|---|---|---|
| 札幌 | 札幌 | 支部1 | 0 |
3 |
2 |
| 札幌 | 支部2 | 0 | 4 | 3 | |
| 旭川 | 支部1 | 0 | 5 | 4 | |
| 旭川 | 支部2 | 0 | 6 | 5 | |
| 仙台 | 青森 | 支部1 | 1 | 3 | 6 |
| 青森 | 支部2 | 1 | 4 | 7 | |
| 岩手 | 支部1 | 1 | 5 | 8 | |
| 岩手 | 支部2 | 1 | 6 | 9 | |
| 秋田 | 支部1 | 1 | 7 | 10 |
ですから、ループはiの中に、jのループが入る二重ループになります。
変数(i)
iは全国画面で「所在地・代表電話」のリンクがある間、繰り返します。
「所在地・代表電話」のリンクを取得するコードは
driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]')で、リンク要素を111個取得できました。そして、1つ1つのリンクは
driver.find_elements_by_xpath(('//a[contains(text(),\'所在地・代表電話\')]')[i].click()で操作しました。
よって、iが取る値は、0~リンク要素の個数 – 1(=110)となります。(0始まりなので、ラストは110)
要素の個数は len()関数を用いて
len(driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]'))で取得できるので、iのループは
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]'))
#count_iは111となる
for i in range(count_i) #0~110まで繰り返す
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]')[i].click()となります。
変数(j)
jは地域画面で、表の行のリンク先がある間、繰り返します。要素を取得するコードは
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a') #jは3始まりでしたので、上記のコードで要素が存在する間、
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a').click()クリック処理を実施します。
要素が存在するかを判定するには
- 要素の個数が0でないことを判定
- 要素が存在しない場合、クリックすると例外が発生するので、例外をキャッチ
と二通りの方法があります。今回は1の方法を取ります。
要素の個数を知るには、変数iの時に使用したように、まずfind_elements関数で要素のリストを取得し、次にlen関数でリストの個数を得ます。
len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) #要素の個数これが0より大きければ、繰り返し処理を継続します。
j = 3
while len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a').click()
j += 1変数(k)
kはExcelシートの行を管理します。2始まりでExcelに出力するたびに、1加算します。
#Excel出力 kは2始まり
ws1.cells(k, 1).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/h3').text
ws1.cells(k, 2).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
k += 1ループ処理
上記のi、j、kの処理を合わせます。
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]'))
#count_iは111となる
for i in range(count_i) #0~110まで繰り返す
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]')[i].click()
j = 3
while len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a').click()
#Excel出力 kは2始まり
ws1.cells(k, 1).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/h3').text
ws1.cells(k, 2).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
k += 1
j += 1修正点
- Kに初期値(2)を与えます
- while文の繰り返し処理では、毎回の処理開始時に、地域画面が表示されている必要があります。
→ while文の最後でブラウザの戻るボタンを押す処理を入れます。
k = 2
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]'))
#count_iは111となる
for i in range(count_i) #0~110まで繰り返す
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath('//a[contains(text(),\'所在地・代表電話\')]')[i].click()
j = 3
while len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a').click()
#Excel出力
ws1.cells(k, 1).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/h3').text
ws1.cells(k, 2).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
k += 1
j += 1
driver.back() #ブラウザの戻る完成スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
j = 3
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').click()
#Excel出力
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
driver.back() #ブラウザの戻る
j += 1
k += 1
#Excel保存
wb1.save(book_path)
wb1.close()
Chromeでは、事前にウィンドウの倍率を100%にしておかないと、リンクのクリックができません。
スクリプトの実行
Pythonで作成したSeleniumのスクリプトを実行します。
コマンドプロンプトから実行する場合
- Windows10の場合
「スタートメニュー」「 Windows システムツール」「コマンドプロンプト」 - Windows8の場合
「すべてのアプリ」 「 Windows システムツール」「コマンドプロンプト」 - Windows7の場合
「スタートメニュー」「すべてのプログラム」「アクセサリ」「コマンドプロンプト」
コマンドプロンプトの画面で
python 実行ファイル名
プログラムが起動すると、ブラウザとExcelが開き、住所と電話番号を収集します。
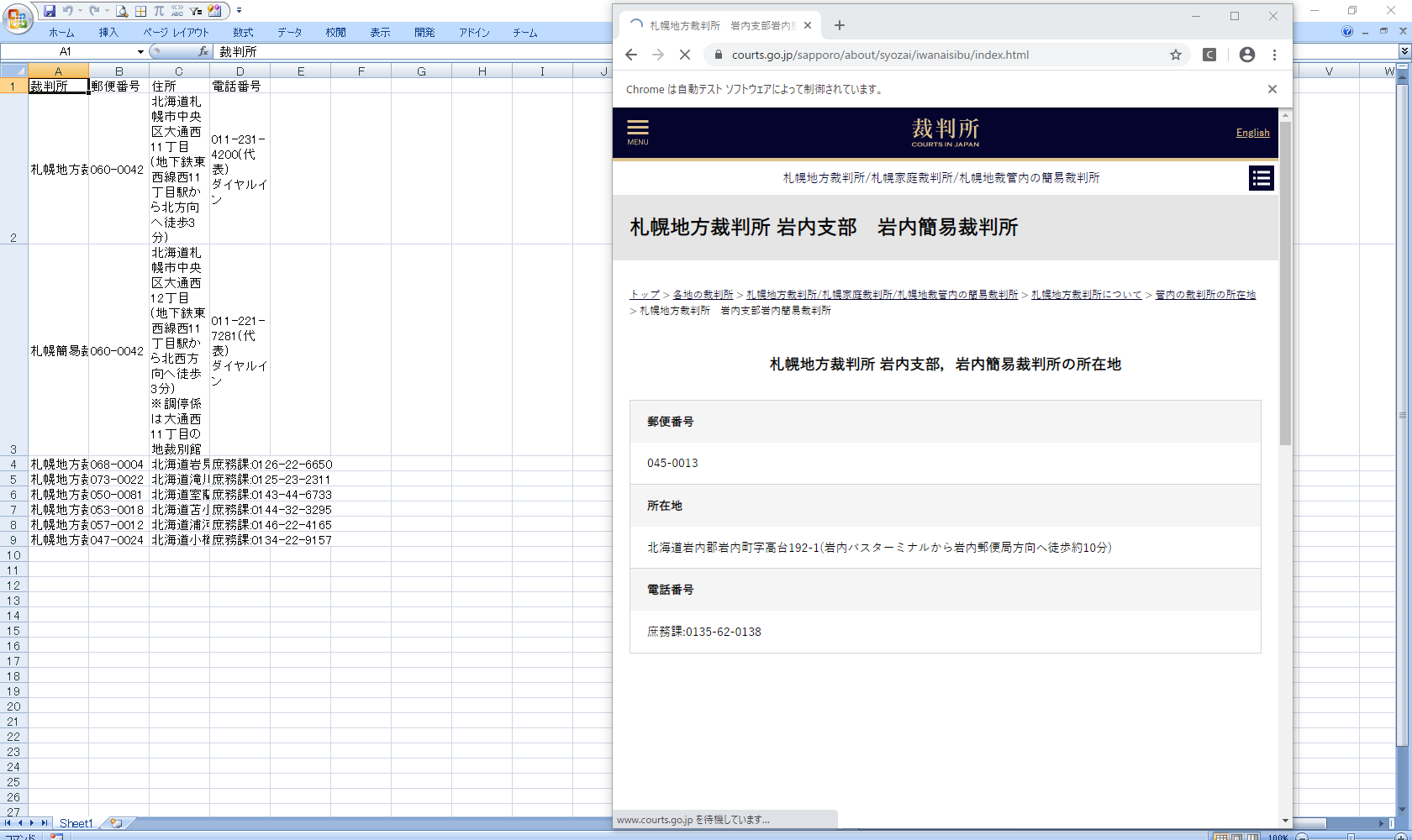
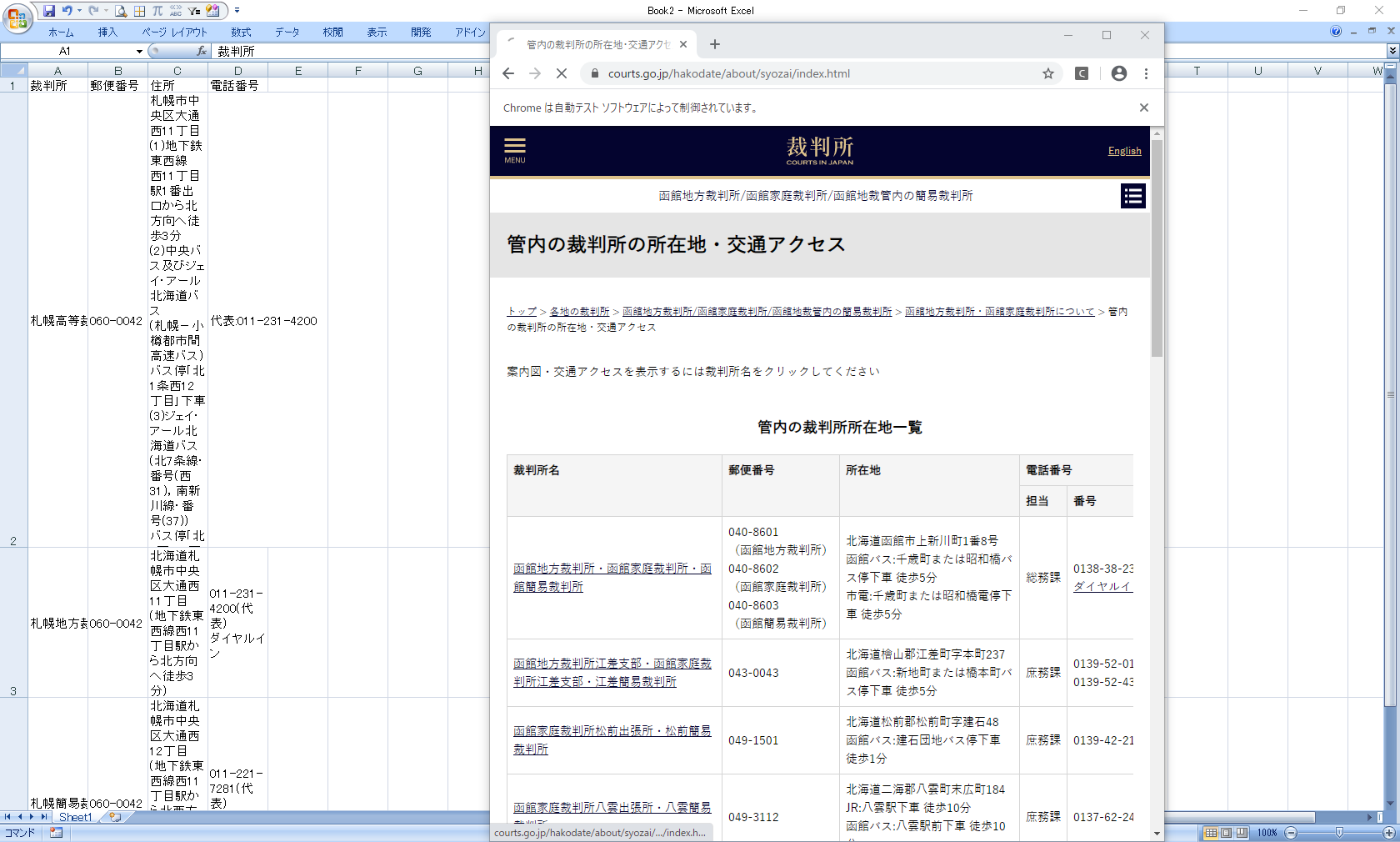
なんと、一番最初の札幌高裁のデータが取得できていません。
その後、エラーが発生しました。
5.エラーの修正
5-1.タブの切り替え
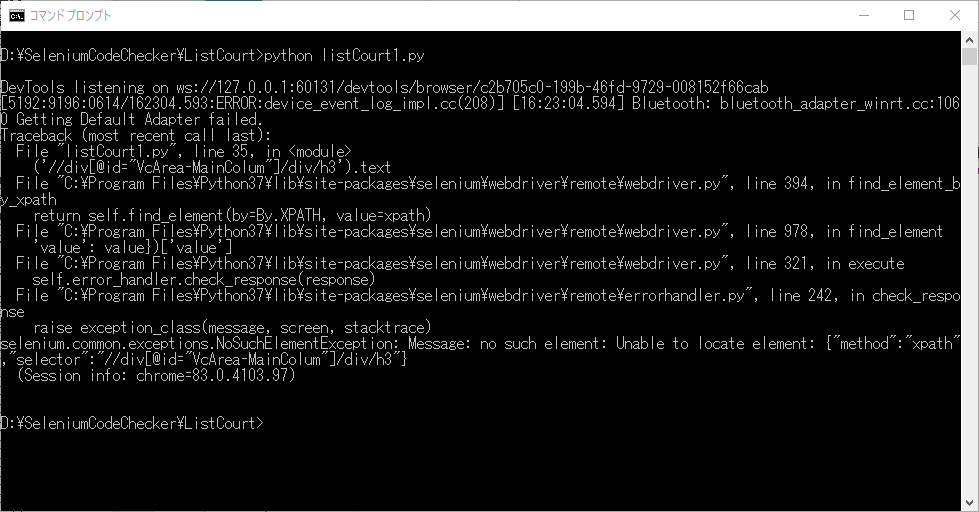
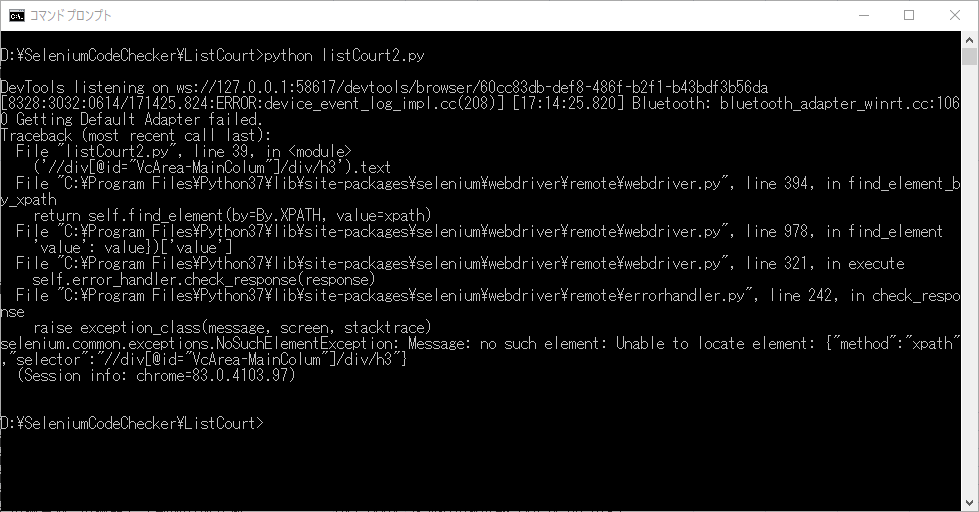
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//div[@id="VcArea-MainColum"]/div/h3"}要素が存在しないようです。ブラウザの状態を見てみます。
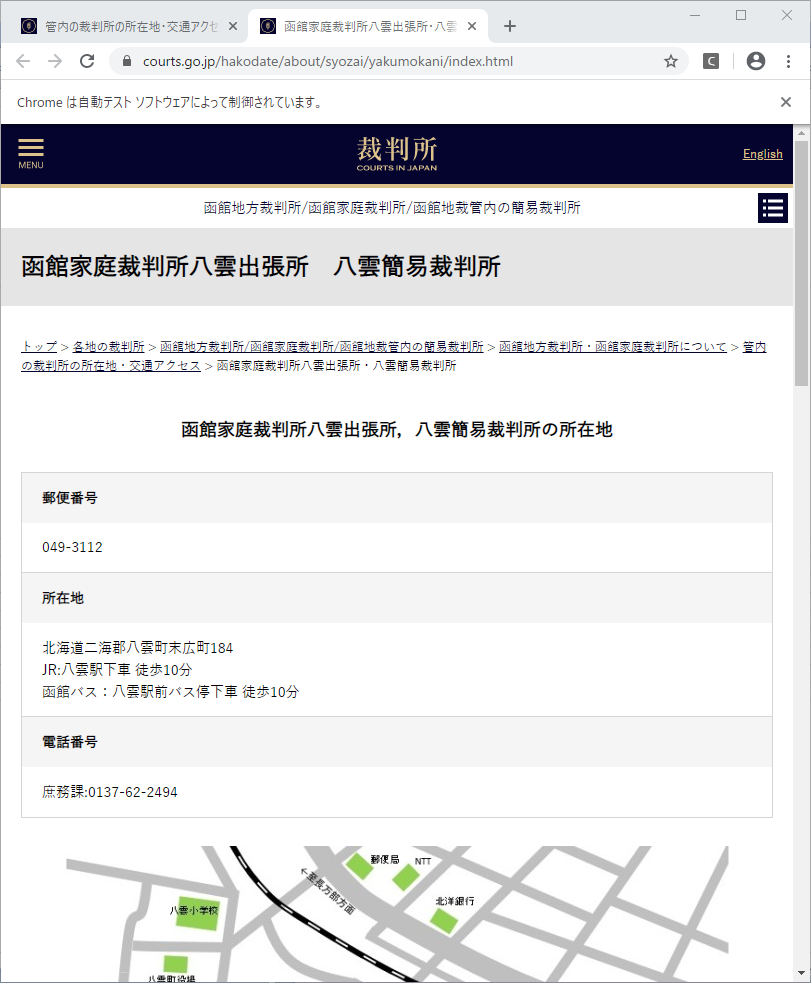
上部を見てもらえると分かりますように、八雲出張所だけ、なぜか別タブで開かれています。
実際に、地域一覧画面に戻って「八雲出張所」のリンクをクリックすると、新規タブが開きます。
本来は他と同じように、同一タブ内で画面が切り替わるのが正しいような気もしますが、依頼して修正してもらう訳にもいきません。ここがRPAのツライところです。
タブの切り替え
Seleniumはタブの切り替わりを自動では処理しませんので、明示的に処理対象のタブを切り替える必要があります。【driver.window_handles】と【driver.switch_to.window】を使用します。
Seleniumが起動したブラウザのウィンドウ(タブ)は、window_handlesというリスト(配列)で管理されています。
- タブが1枚:window_handles[0]
- タブが2枚:window_handles[0],window_handles[1]
- タブが3枚:window_handles[0],window_handles[1],window_handles[2]
そして、タブを切り替えるときは、switch_to_window関数に切り替え先のハンドルを渡します。
driver.switch_to.window(window_handles[1])ただし今回は、最終的に開いたタブを閉じて、元のタブに戻す必要があるので、現在のタブのハンドルを取得する【driver.current_window_handle】を用いて、
before_handle = driver.current_window_handle #現在のタブのハンドルを保存
#タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(window_handles[1])
(処理終了後)
driver.close() #新規タブを閉じる
driver.switch_to.window(before_handle) #元のタブに戻すとします。
5-2.札幌高裁のXPath
XPathの違い
一番最初の札幌高裁のデータが取得できていません。XPathを調べてみます。

ここで指定しているXpathは //div//tr[j]/td[1]/a (jは3始まり)でしたが、札幌高裁の場合は、jが1になるようです。このままでは、他のケースと共有できません。
<tr>タグは表の行を示しています。HTMLソースを見ると、以下のようになっていました。


対応策
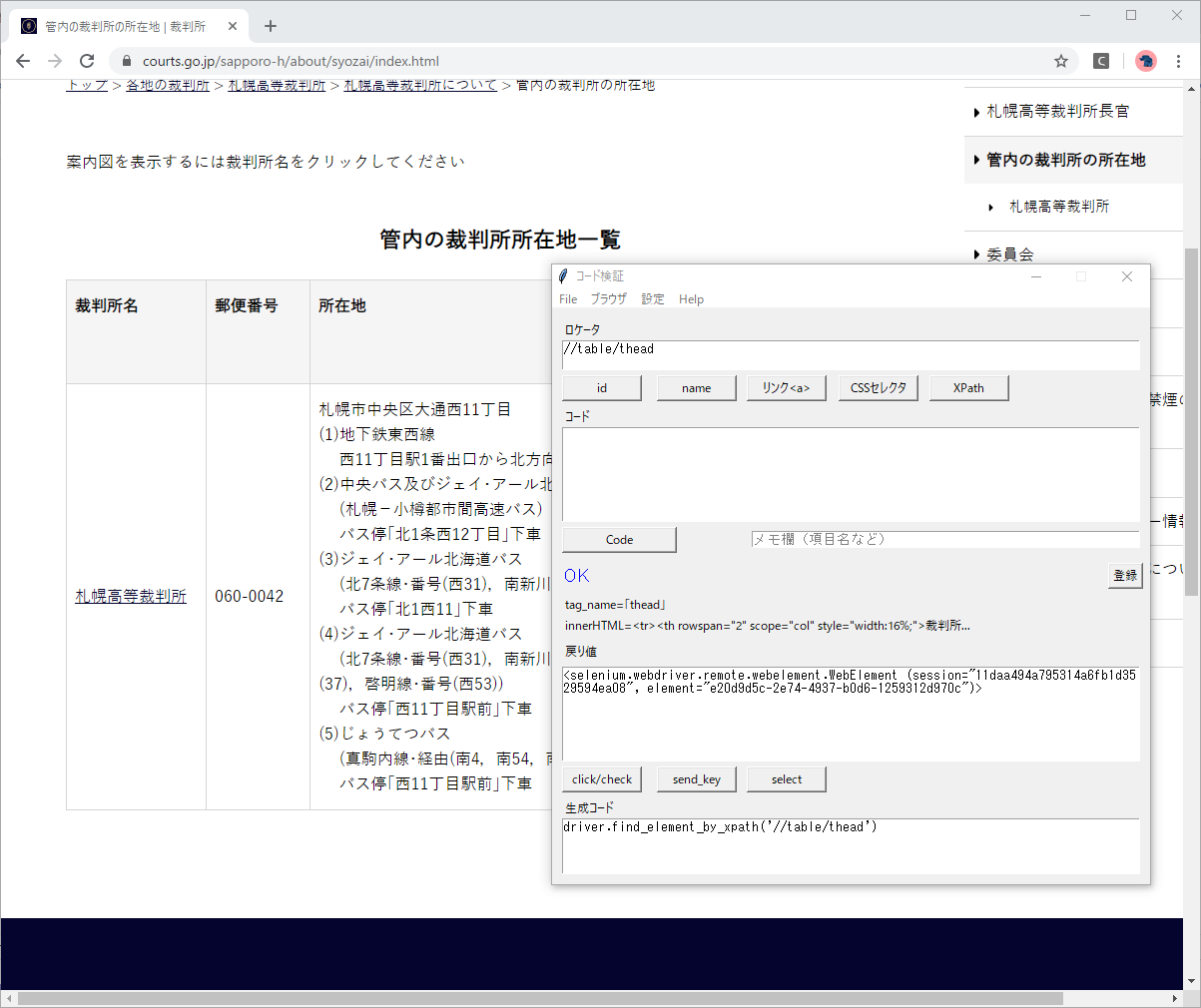
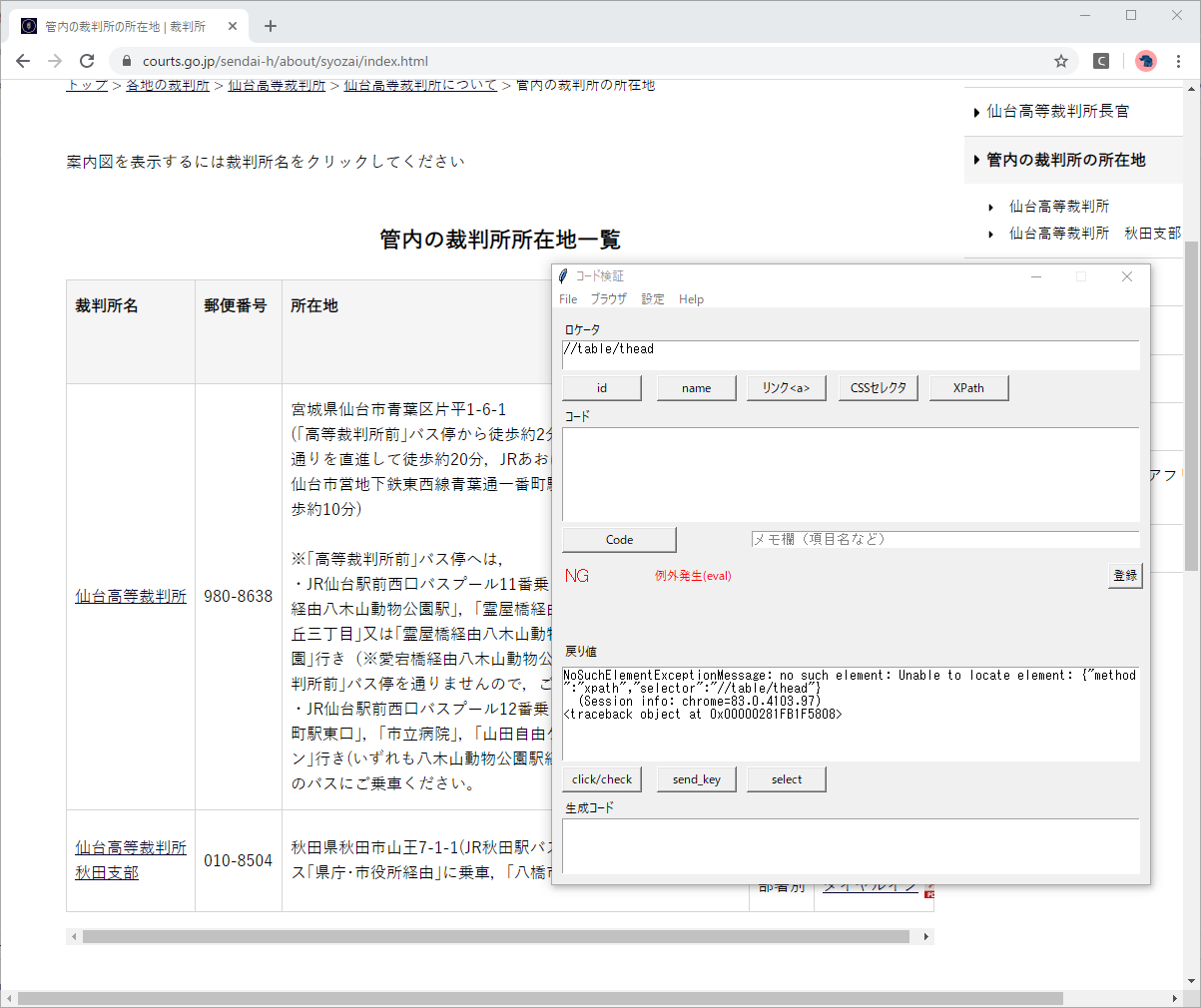
変数jは、表のヘッダー部(tr[1],tr[2])を除いて3から始まることにしていますが、ヘッダー部が<thead>タグの場合は、jを1から始めることにします。
<thead>部分のXPathは //table/thead ですので、XPath検証ツールで
- 札幌高裁では要素が1個しかないこと
- 通常のケースでは0個であること
を確認します。
修正コード
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3修正スクリプト
上記の修正コードを書き加えます。
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
before_handle = driver.current_window_handle # 現在のタブのハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#Excel保存
wb1.save(book_path)
wb1.close()
スクリプトの実行
コマンドプロンプトから実行します。

札幌高裁のデータが取得できています。
エラーが発生しました。
5-3.表のタイトルなし
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//div[@id="VcArea-MainColum"]/div/h3"}XPathが //div[@id="VcArea-MainColum"]/div/h3 の要素(裁判所名)が存在しないとのことです。ブラウザを見てみましょう。
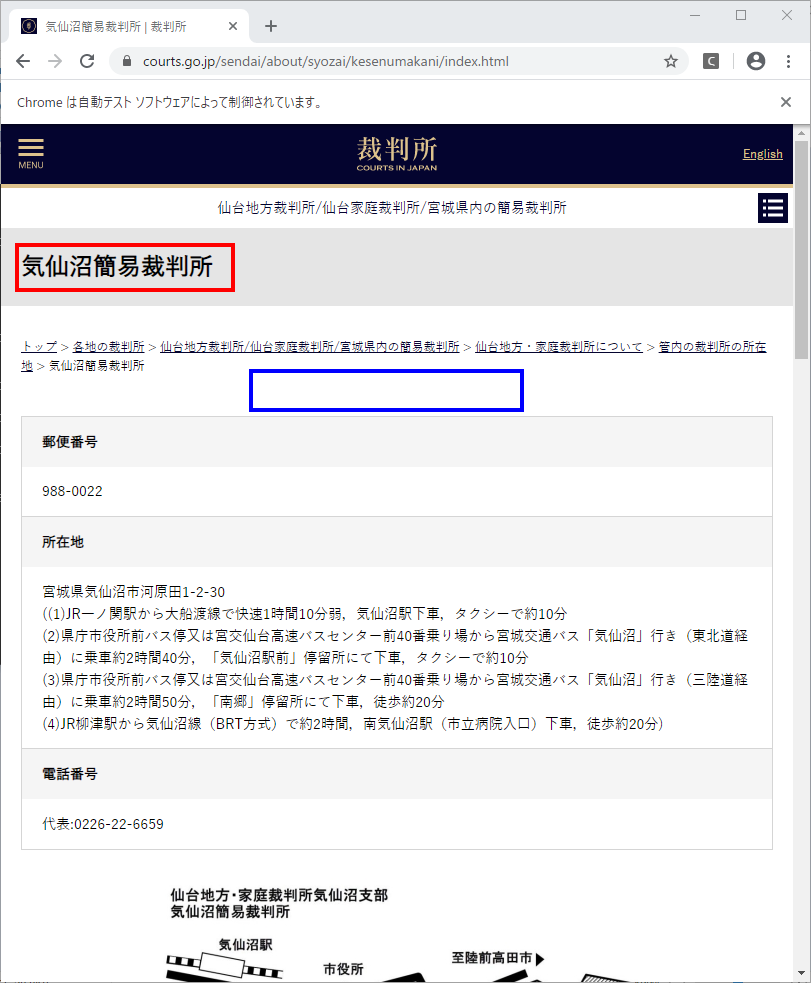
やはり、表の上部の裁判所名がありません。仕方がないので、左上のヘッダー部分から編集します。
ヘッダー部のXPathを、XPath取得ツールで取得します。
| XPath | 操作 |
|---|---|
| // div[ @ id = “VcArea-Header"] / div / h2 | テキスト取得 |
要素が存在するかの判定は、変数jのところで記載したように
- 要素の個数が0でないことを判定
- 要素が存在しない場合、クリックすると例外が発生するので、例外をキャッチ
の二通りがあります。
前回は1を適用したので、学習のためにも今回は2を採用します。
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
before_handle = driver.current_window_handle # 現在のタブのハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#Excel保存
wb1.save(book_path)
wb1.close()
スクリプトの実行
修正したスクリプトをコマンドプロンプトから実行します。

またエラーが発生しました。
5-4.知財高裁が別サイト
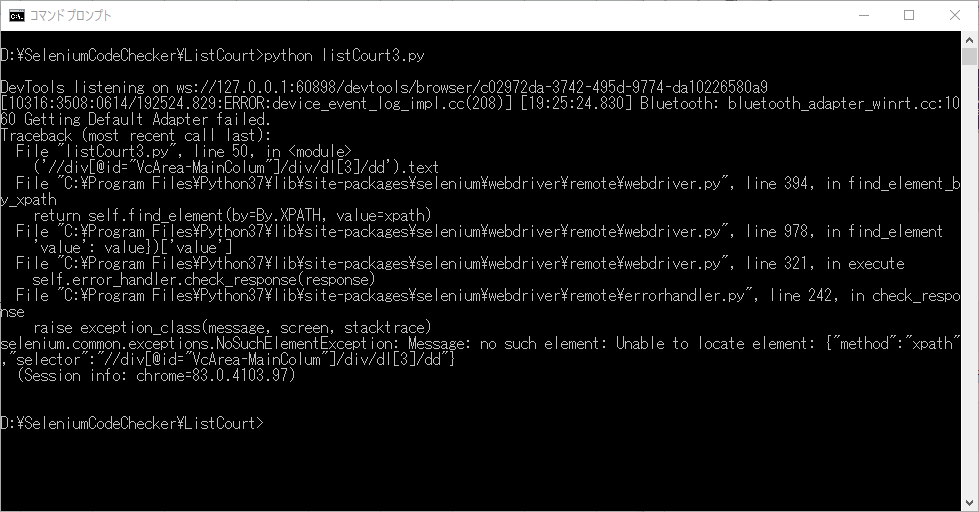
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//div[@id="VcArea-MainColum"]/div/dl[3]/dd"}ブラウザの状態を見てみます。
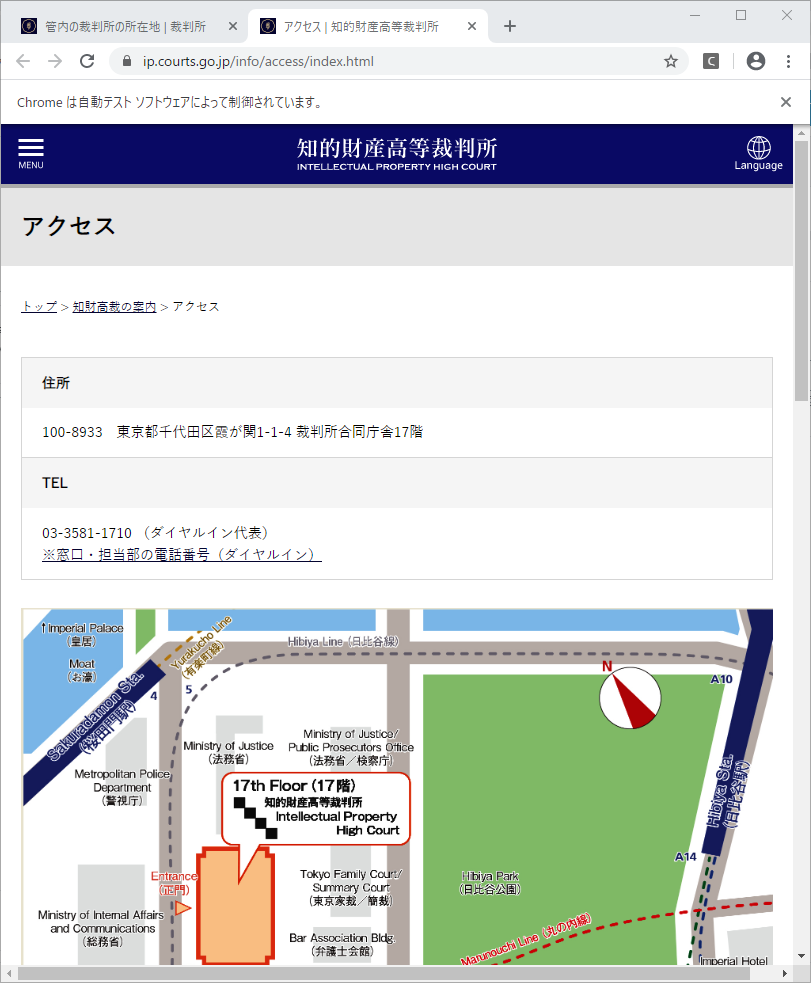
知財高裁だけ、各地の裁判所とは異なるページ内容になっています。

リンク元で、「別サイトへジャンプします」となっています。
知財高裁の対応
1か所だけなので、自動操作はあきらめ、エラー扱いとしてシートに記載します。
しかしながら、知財高裁のリンクをクリックすると別タブが開いてしまうので、
- リンクをクリックしない
- 開いたタブを閉じる
どちらかの対応が必要です。
今回は2で行きます。
#知的高裁エラーハンドリング
if len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # 現在のタブのハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻すなお、知財高裁の住所・電話番号は「東京高裁」経由で取得できます。
捕捉)重複データの扱い
収集したデータを見ますと、簡易裁判所と家庭裁判所を併設しているようなケースでは、簡易裁判所からのリンクと、家庭裁判所からのリンクで、データが重複して記載されています。
いったん、重複分もExcelに出力して、重複データはExcelで削除することにします。
プログラムを組むよりもExcelの標準機能を用いた方が早くて確実です。
修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
#知的高裁エラーハンドリング
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
before_handle = driver.current_window_handle # 現在のタブのハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#Excel保存
wb1.save(book_path)
wb1.close()
5-5.電話番号なし
スクリプトを実行すると、エラーが発生します。
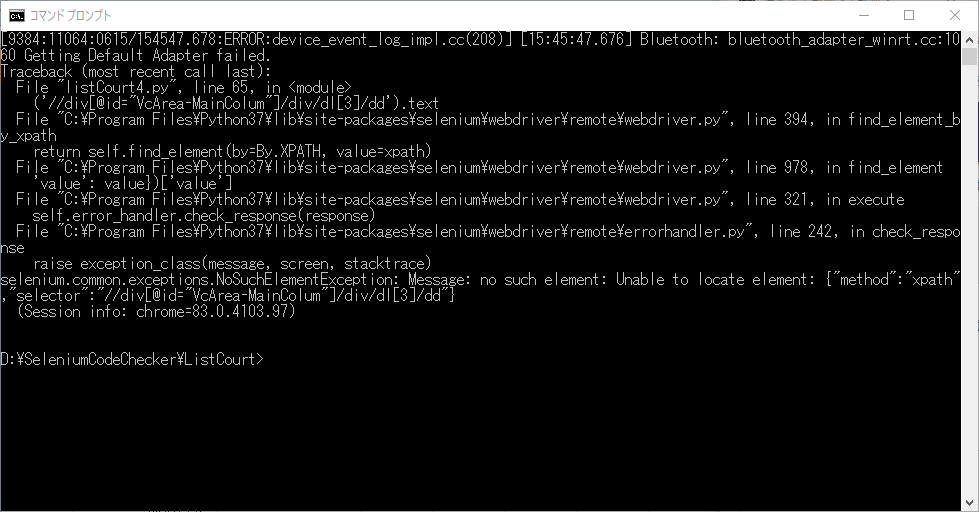
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//div[@id="VcArea-MainColum"]/div/dl[3]/dd"}
電話番号欄が存在しません。
地域画面にダイヤルイン一覧として、pdfファイルが掲載されています。
SeleniumでPDFから文字を取得するのは難しいので、手動で取得するしかないようです。

コードの修正
電話番号の欄が存在する場合のみ、電話番号を取得します。
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
#知的高裁エラーハンドリング
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
before_handle = driver.current_window_handle # 現在のタブのハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#Excel保存
wb1.save(book_path)
wb1.close()
5-6.PDF表示
スクリプトを実行すると、エラーが発生します。
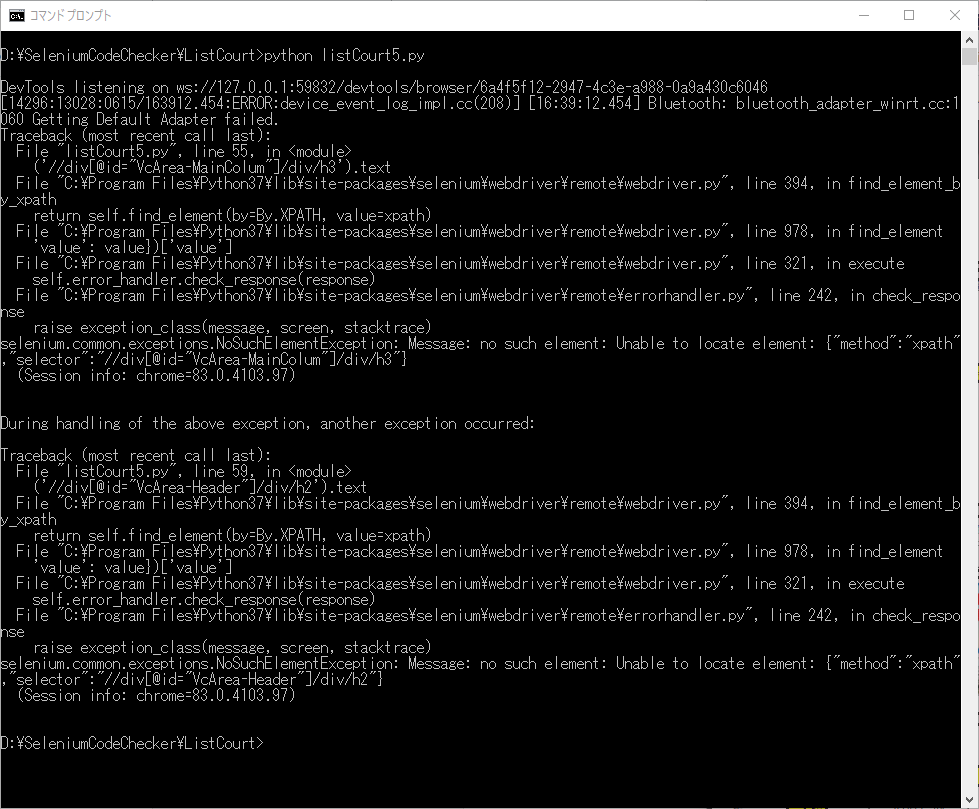
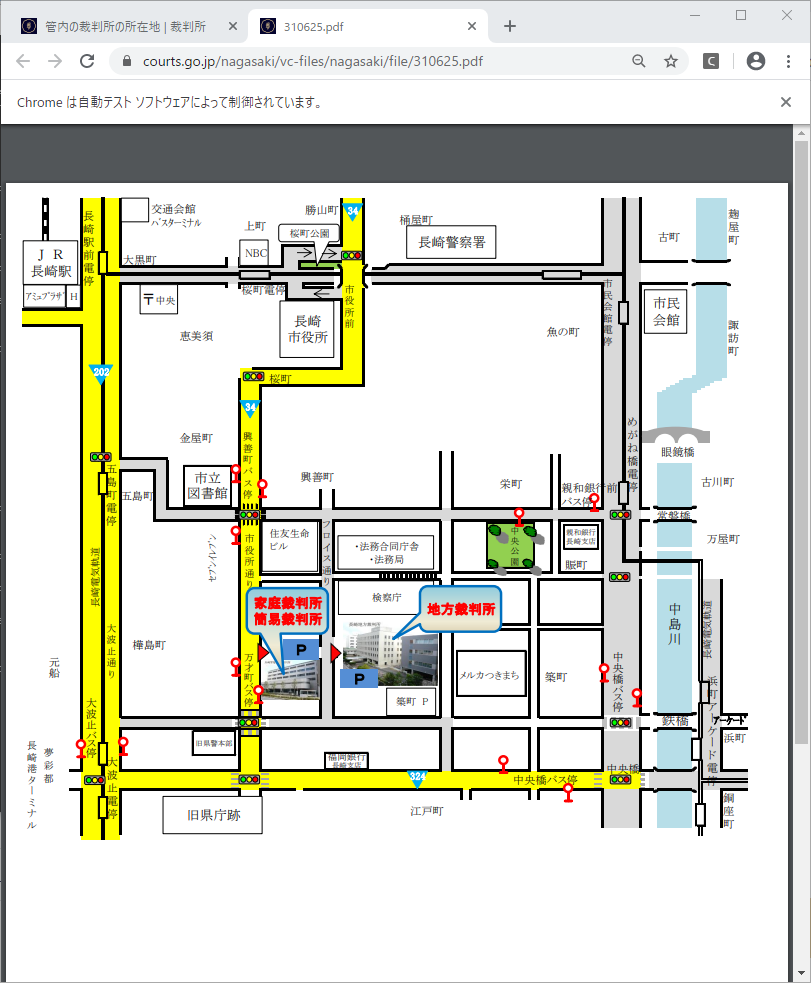
長崎地裁はPDFが表示されます。地域画面の方には、住所・電話番号とも表示されています。
対応方法
地域画面でリンクをクリック後、pdfファイルの場合は、地域画面の情報でExcel出力します。
画面の項目を取得するコードは以下のようになります。
| 項目 | XPath | テキスト取得コード |
|---|---|---|
| 裁判所名 | //div//tr[j]/td[1]/a | driver.find_element_by_xpath('//div//tr[j]/td[1]/a’).text |
| 郵便番号 | //div//tr[j]/td[2] | driver.find_element_by_xpath('//div//tr[j]/td[2]’).text |
| 住所 | //div//tr[j]/td[3] | driver.find_element_by_xpath('//div//tr[j]/td[3]’).text |
| 電話番号 | //div//tr[j]/td[5] | driver.find_element_by_xpath('//div//tr[j]/td[5]’).text |
pdfファイルかどうかは、リンク要素(裁判所名)のURLの末尾が「.pdf」かどうかで判断します。
#リンク先がpdfの場合は遷移無し
url = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').get_attribute('href') #リンク先URL取得
if url[len(url)-4:] == '.pdf': #urlの末尾4文字が'.pdf'
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
#知的高裁エラーハンドリング
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
#リンク先がpdfの場合は遷移無し
url = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').get_attribute('href')
if url[len(url)-4:] == '.pdf': #urlの末尾4文字が'.pdf'
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text
else:
before_handle = driver.current_window_handle # 現在のハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#Excel保存
wb1.save(book_path)
wb1.close()
スクリプトの実行
修正したスクリプトをコマンドプロンプトから実行します。

ようやく例外が発生せずに、終了しました。
5-7.リンクのXPathが異なる
エラー内容
保存されたExcelシートを確認すると、エラーが3か所あります。

知財高裁はエラー扱いとしましたので、問題ありません。1行上に、正常データが取得できています。
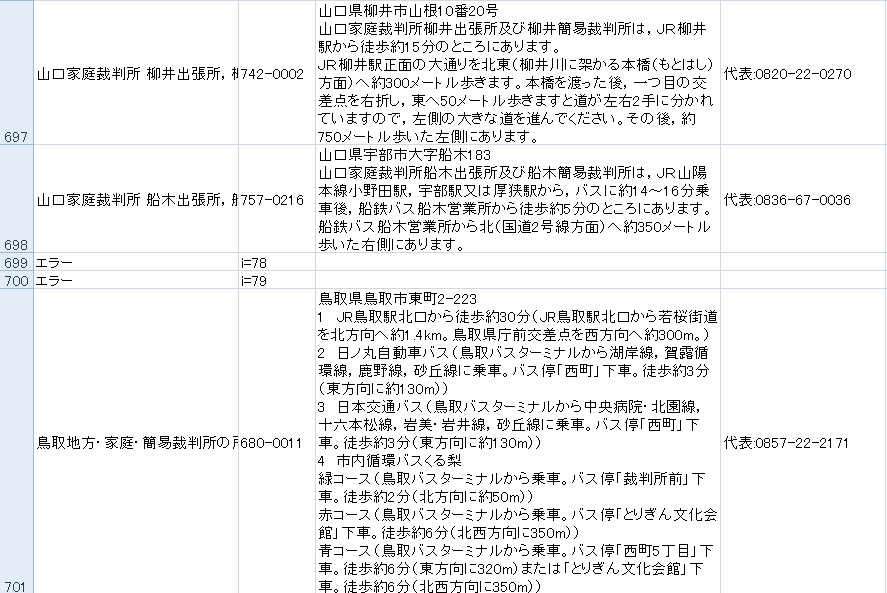
山口と鳥取の間でエラーが発生しています。

鳥取と高松の間でも、エラーが発生しています。
知財高裁エラーのところで、エラー出力する対応のおかげで、エラー発生を知ることができました。
エラー箇所の特定
エラー箇所はどこかを確認します。
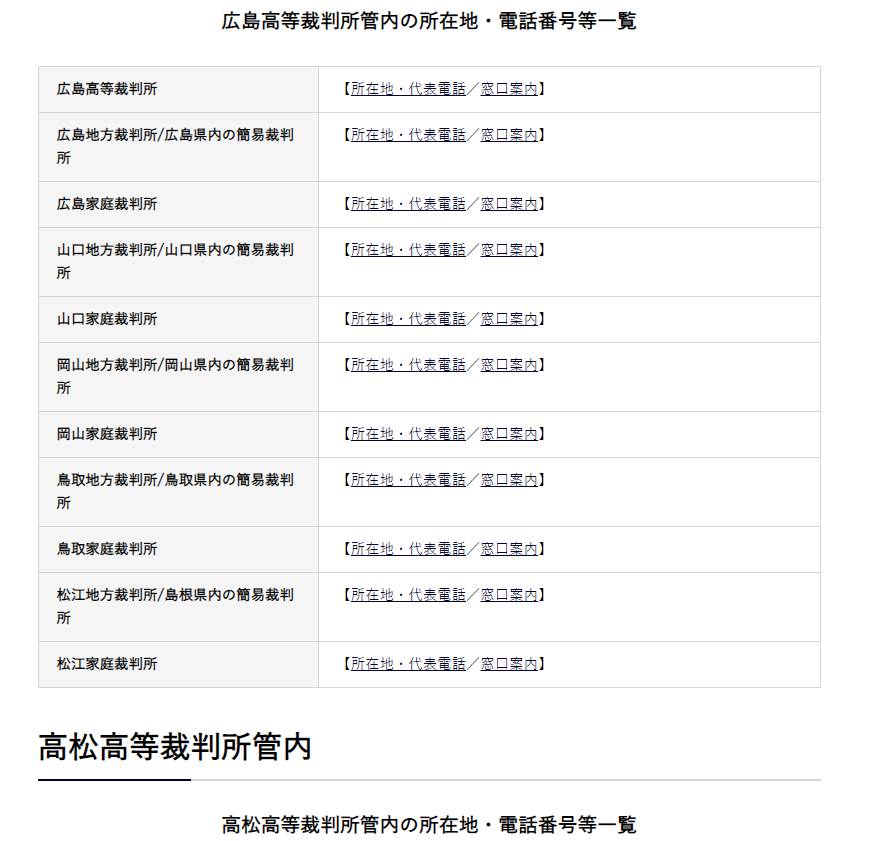
山口と鳥取の間は「岡山」、鳥取と高松の間は「松江」です。
エラー原因(岡山)
岡山の地域画面を見ると、表形式が他のケースと異なります。【地図】をクリックすると詳細画面に遷移します。
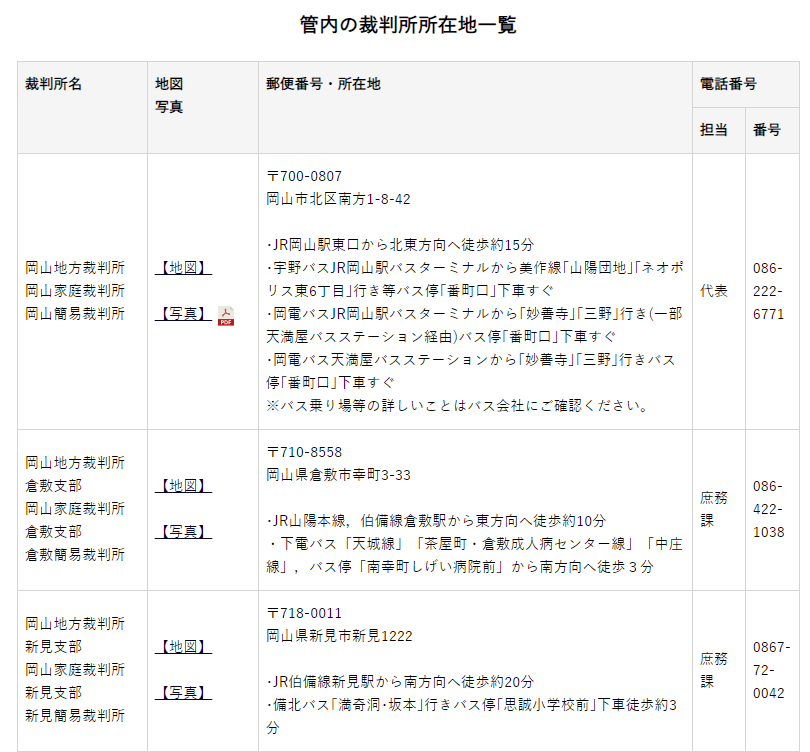
しかも、詳細画面のXPathも異なります。

| 画面 | 項目 | XPath | 備考 |
|---|---|---|---|
| 地域 | 【地図】 | //div//tr[j]//a[1] | jは3始まり |
| 詳細 | 裁判所名 | //div[@id="VcArea-MainColum"]/div//caption | |
| 郵便番号 | //div[@id="VcArea-MainColum"]/div//tr[1]/td | ||
| 所在地 | //div[@id="VcArea-MainColum"]/div//tr[2]/td | ||
| 電話番号 | //div[@id="VcArea-MainColum"]/div//tr[3]/td |
さらには、支部については別タブで表示されます。
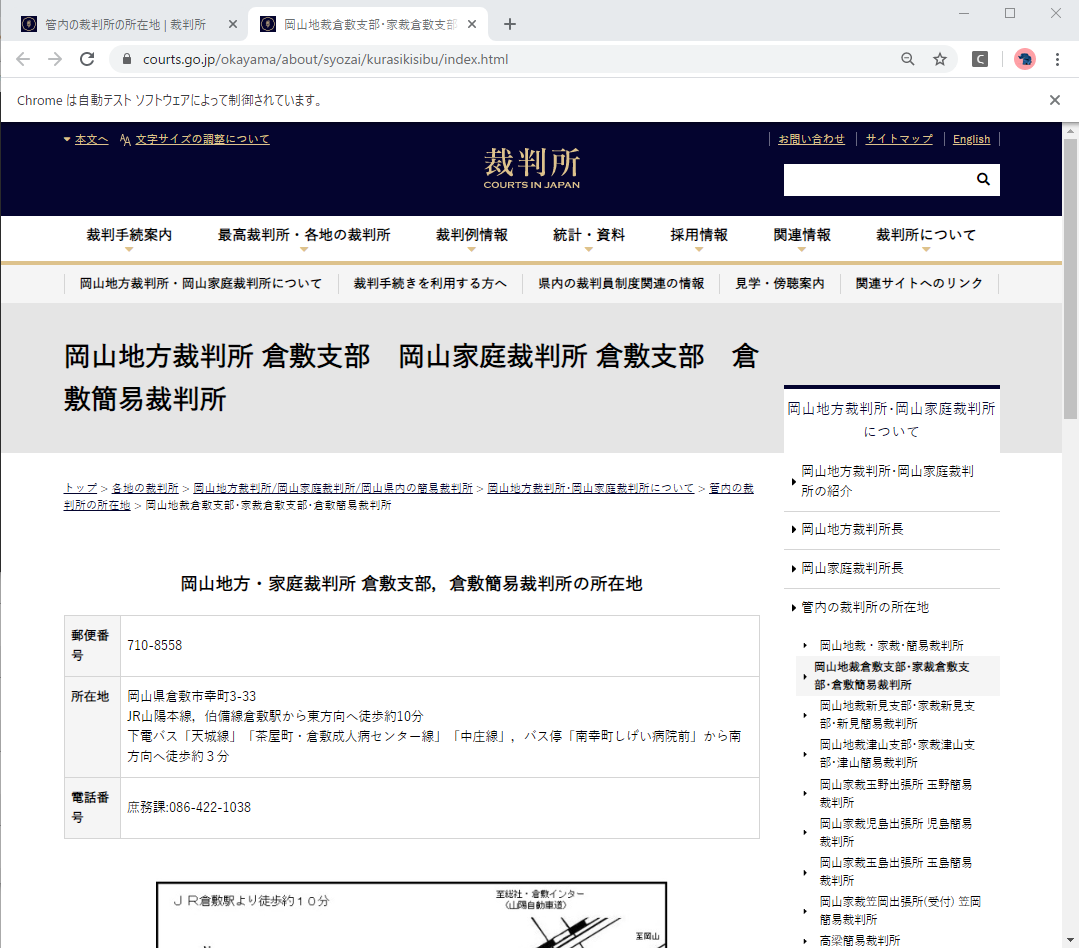
エラー原因(松江)
こちらも地域画面でのクリック項目が異なります。
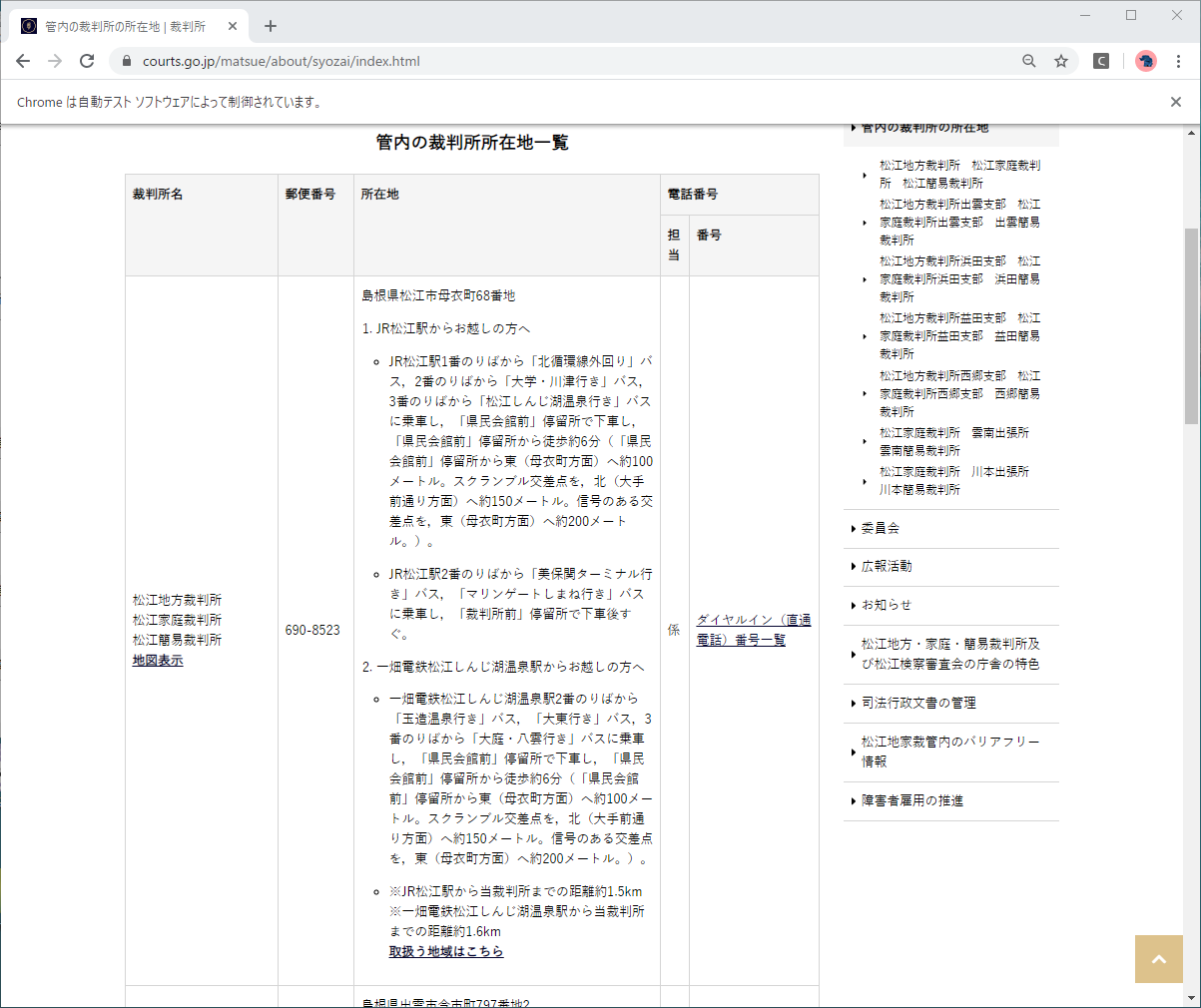
| 画面 | 項目 | XPath |
|---|---|---|
| 地域 | 地図表示 | //div//tr[3]/td[1]//a |
詳細画面のXPathは他と同じですが、新規タブで表示されます。
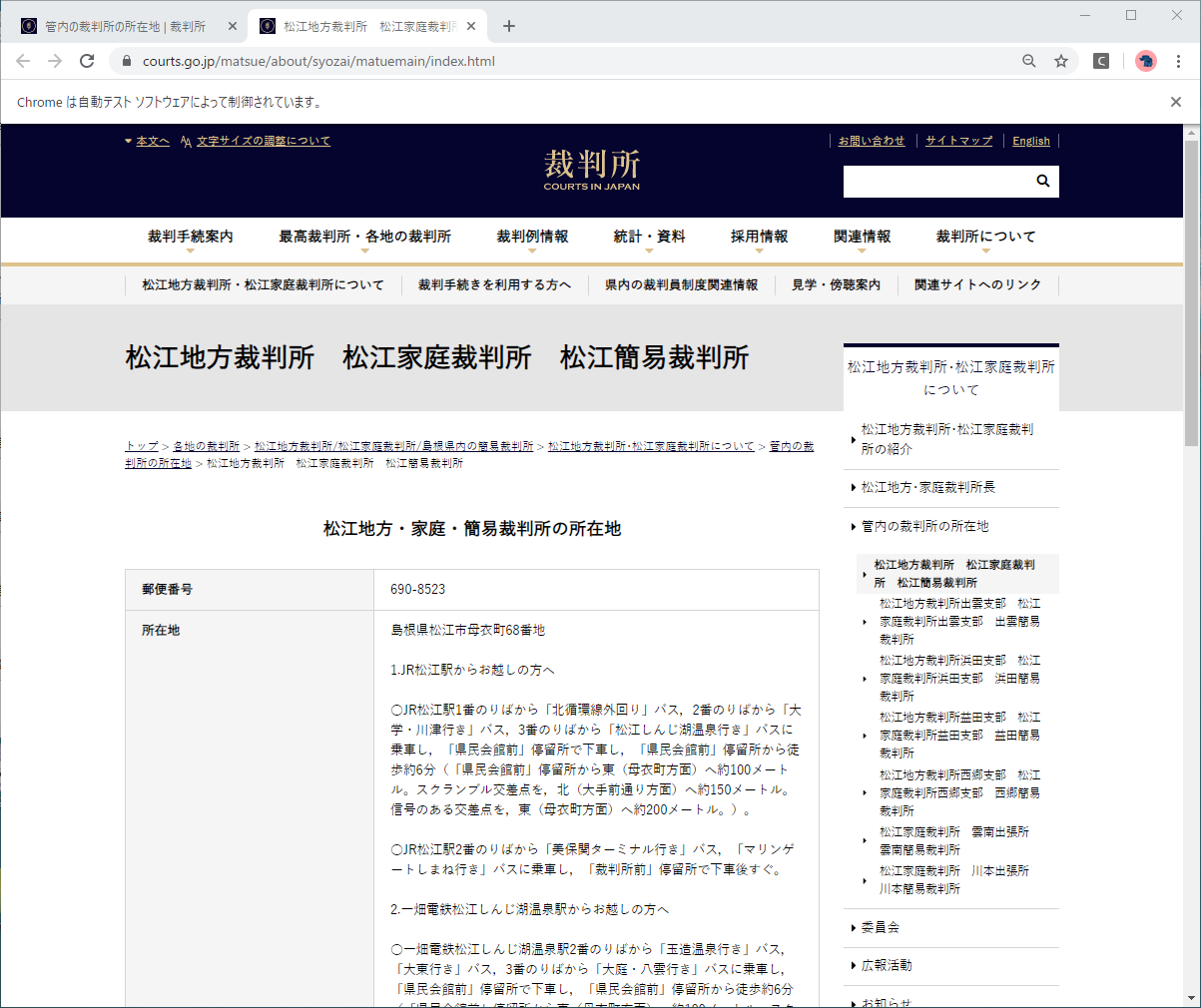
対応方法
以上から全体として、地域画面での場合分けは以下のようになります。
| 地域 | リンクのXPath | 処理 |
|---|---|---|
| 知財高裁 | リンク要素なし | エラー |
| 岡山 | //div//tr[j]//a[1] | 独自処理 |
| 松江 | //div//tr[j]/td[1]//a | 通常処理 |
| その他 | //div//tr[j]/td[1]/a |
元のコード
#知的高裁エラーハンドリング
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
while len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
#リンク先がpdfの場合は遷移無し
url = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').get_attribute('href')
if url[len(url)-4:] == '.pdf':
(処理)
else:
before_handle = driver.current_window_handle # 現在のハンドルを保存
driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a').click()
これまでは、地域画面でのリンク要素 //div//tr[j]/td[1]/a をwhile文の判定条件にしていました。
しかし、通常ケース //div//tr[j]/td[1]/a 以外に、松江のリンク //div//tr[j]/td[1]//a も判定条件に加えなければなりません。
そこで、変数を用いて、リンク要素を先に変数に代入します。
link = None
#通常ケース
if len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')
#松江
elif len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]//a')
#知財高裁はそのまま(link=None)
elif len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
while link is not None: #通常ケース&松江
#リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url)-4:] == '.pdf':
(処理)
else:
before_handle = driver.current_window_handle # 現在のハンドルを保存
link.click()
while文の継続条件が「変数link がNoneでないこと」に変わりましたので、ループ処理の最後に、次のリンク要素を変数linkに代入する処理を追加します。
while link is not None: #通常ケース&松江
(ループ処理)
j += 1
k += 1
#通常ケース
if len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
#Excel保存
wb1.save(book_path)
wb1.close()
個別に岡山の対応を追加します。
#岡山
if len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath('//div//tr[' + str(j) + ']//a[1]')) > 0:
before_handle = driver.current_window_handle # 現在のハンドルを保存
driver.find_element_by_xpath('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#詳細画面も独自形式
ws1.cells(k, 1).value = \
driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div//caption').text
ws1.cells(k, 2).value = \
driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text
ws1.cells(k, 3).value = \
driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text
ws1.cells(k, 4).value = \
driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
完成スクリプト
上記の対応を合わせます
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#列幅の設定
xw.Range('a:a').column_width = 25
xw.Range('b:b').column_width = 9
xw.Range('c:c').column_width = 50
xw.Range('d:d').column_width = 20
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None #地域画面のリンク要素
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
#松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
#岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
before_handle = driver.current_window_handle # 現在のハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
#通常ケース&松江
while link is not None:
#リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url)-4:] == '.pdf': #urlの末尾4文字が'.pdf'
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text
else:
before_handle = driver.current_window_handle # 現在のハンドルを保存
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
# while文の次の条件を設定
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
#Excel保存
wb1.save(book_path)
wb1.close()
動画デモ用に、Excel列幅の設定(13~17行)、アクティブセルを画面内に表示する処理(145行)を追加しています。
動画
実行結果
終了画面
結果ファイル
ここから、なるべく実用的なデータにしていきたいと思います。長くなりましたので次回にします。