Webスクレイピングで営業リストを作成する(2)
前回の裁判所所在地のExcelシートを整形する方法を考えます。
下準備
フィルタの設定
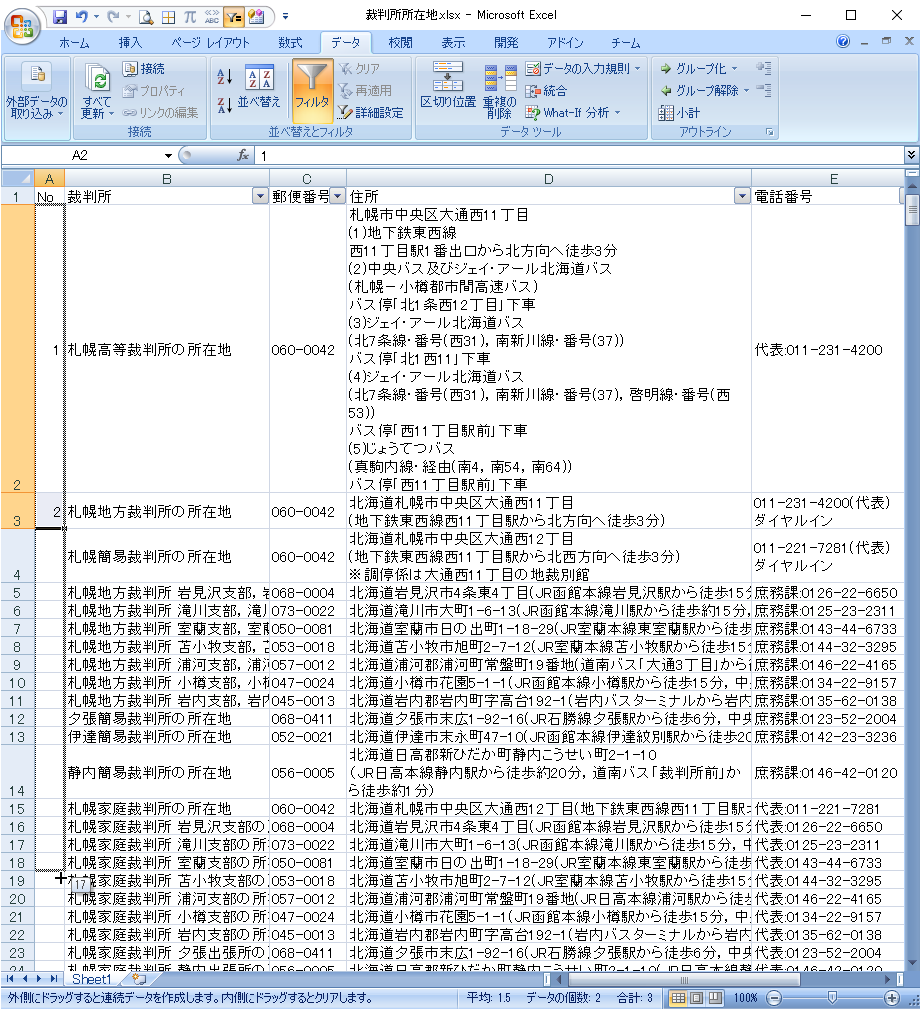
ファイルを開きます。件数は995件です。
先頭行にフィルタを設定します。
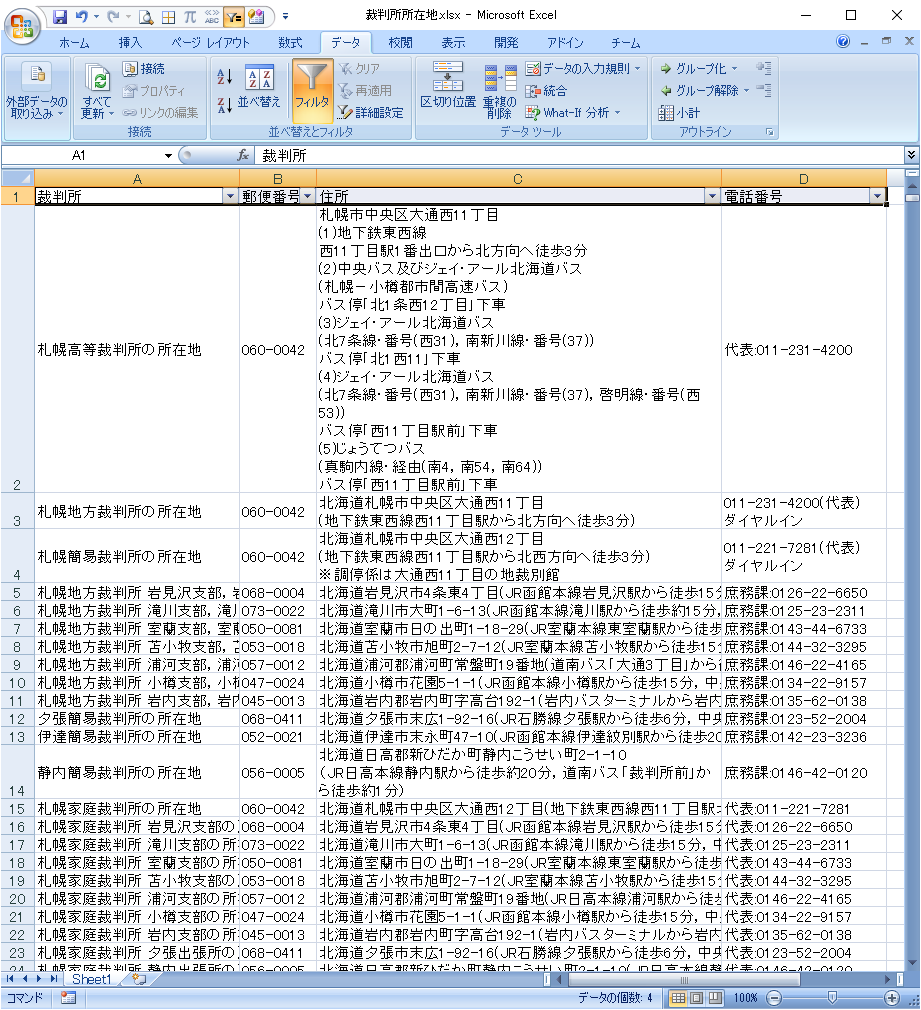
エラーデータの削除
A列からエラーデータを抽出します。
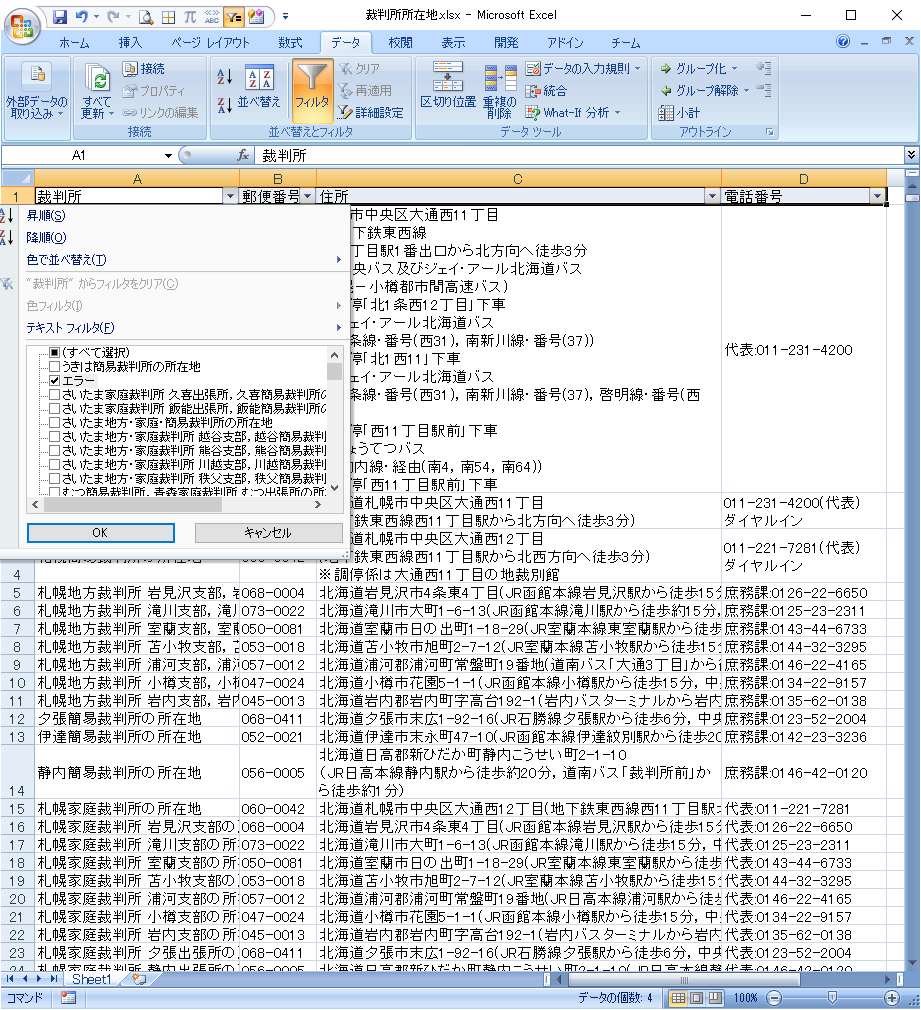
249行目「i=23」がエラーです。知財高裁が別サイトのために例外が発生するエラーでした。
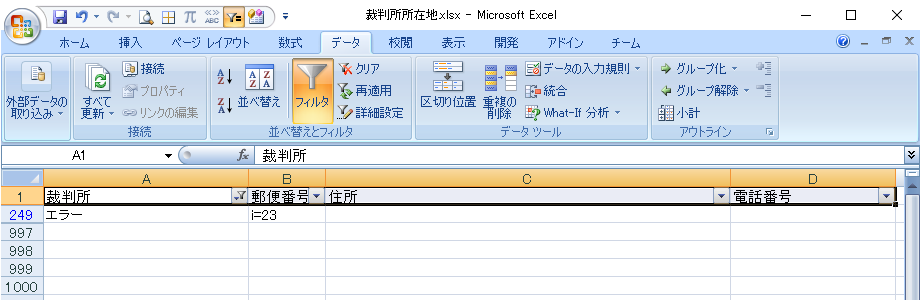
知財高裁のデータは、東京高裁経由で取得しているので、エラー行を削除します。
重複データの削除
続いて重複データを消します。
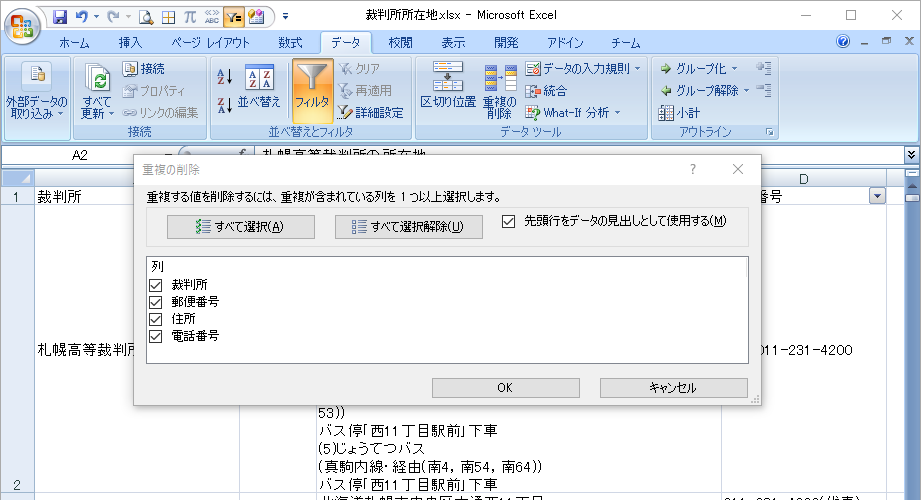
重複データ440個が消され、554個が残りました。
最初の順番を保存
今後、データを並べ替えた場合などに、元の順番に戻せるように、列を追加して、最初の順番を保存しておきます。
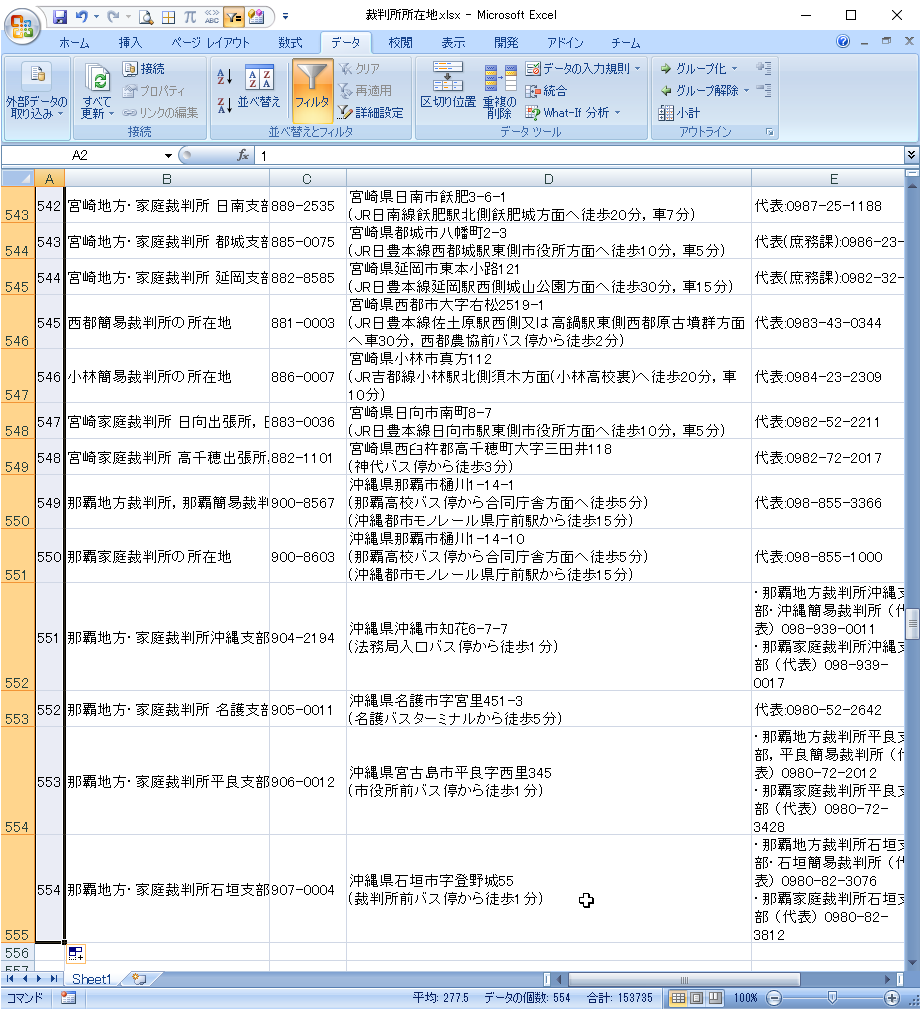
一番左列に「No」を追加し、「1,2」を入力。
Excelのオートフィルで順番を増やしていきます。
554まで、Noが振られました。
データの整備
分類欄の追加
標準データ以外の対応を考えるため、標準外のデータを抽出できるよう、分類欄を追加します。
B~E列を追加(裁判所名、郵便番号、住所、電話番号)
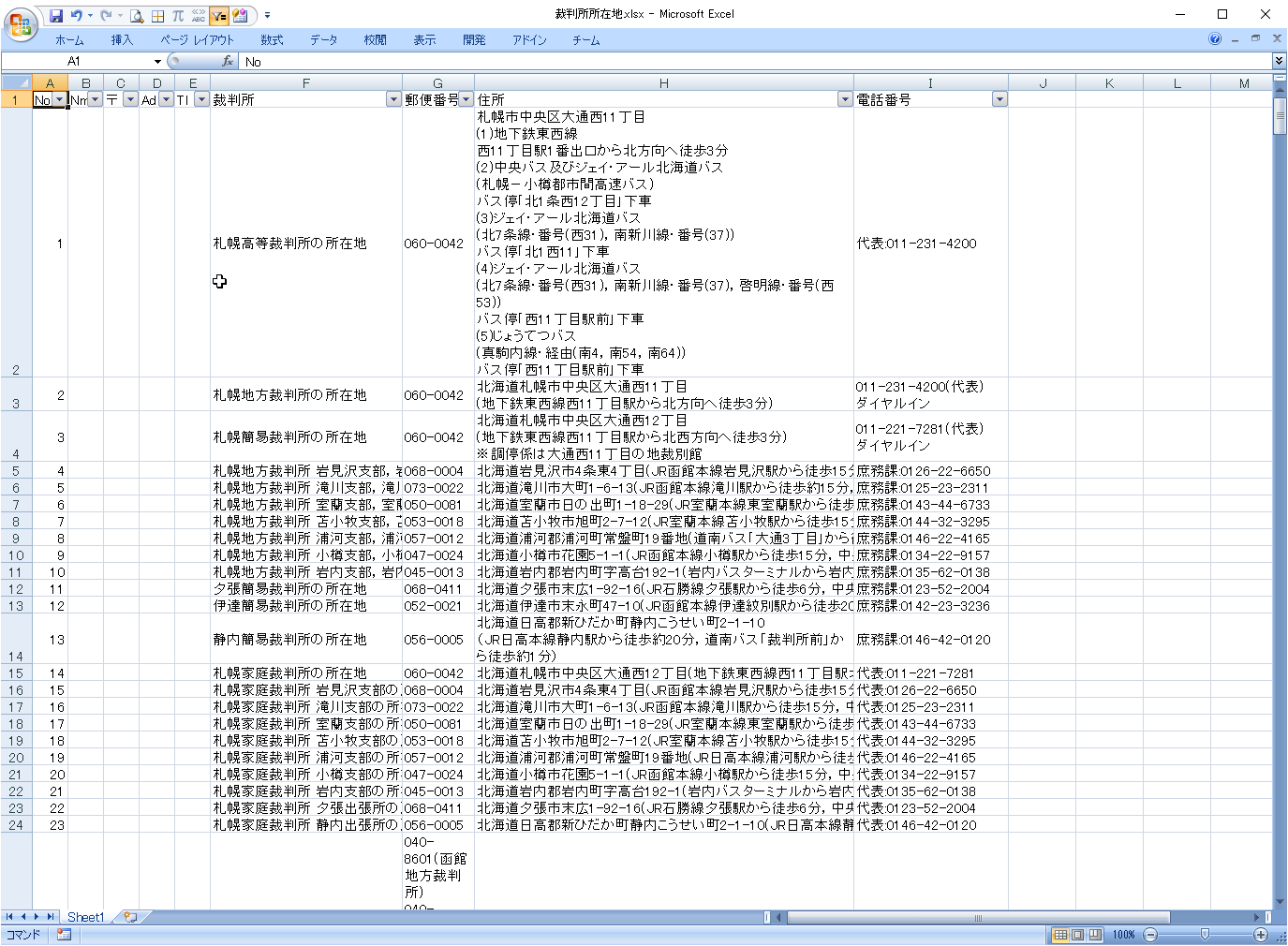
裁判所名
不要文言の削除
裁判所のフィルターをクリックして、裁判所名のリストを表示します。
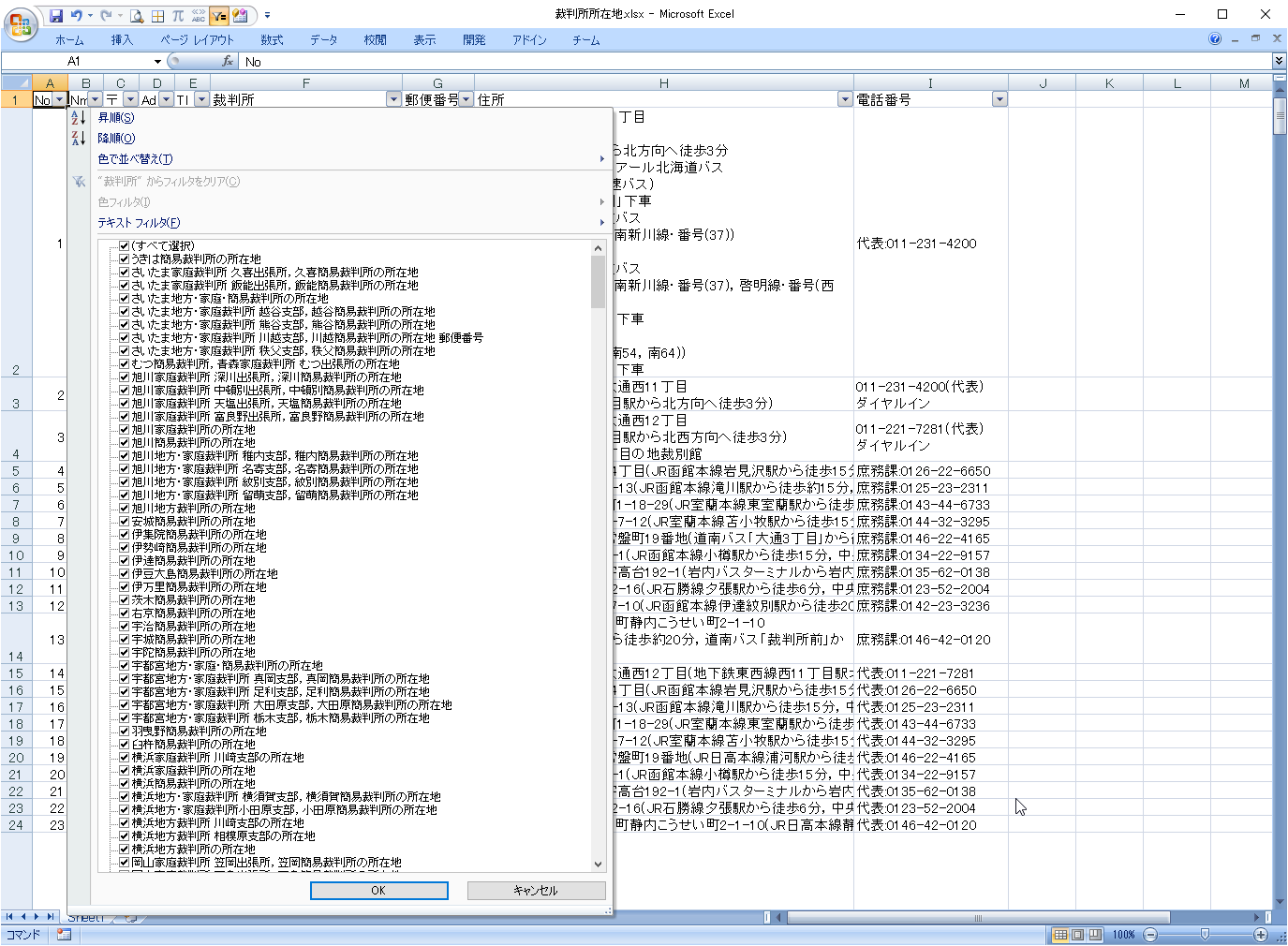
『○○裁判所の所在地』と書かれているものが多いです。「の所在地」を取り除くことを考えます。
まず、整形後の裁判所名を出力する列を追加します。
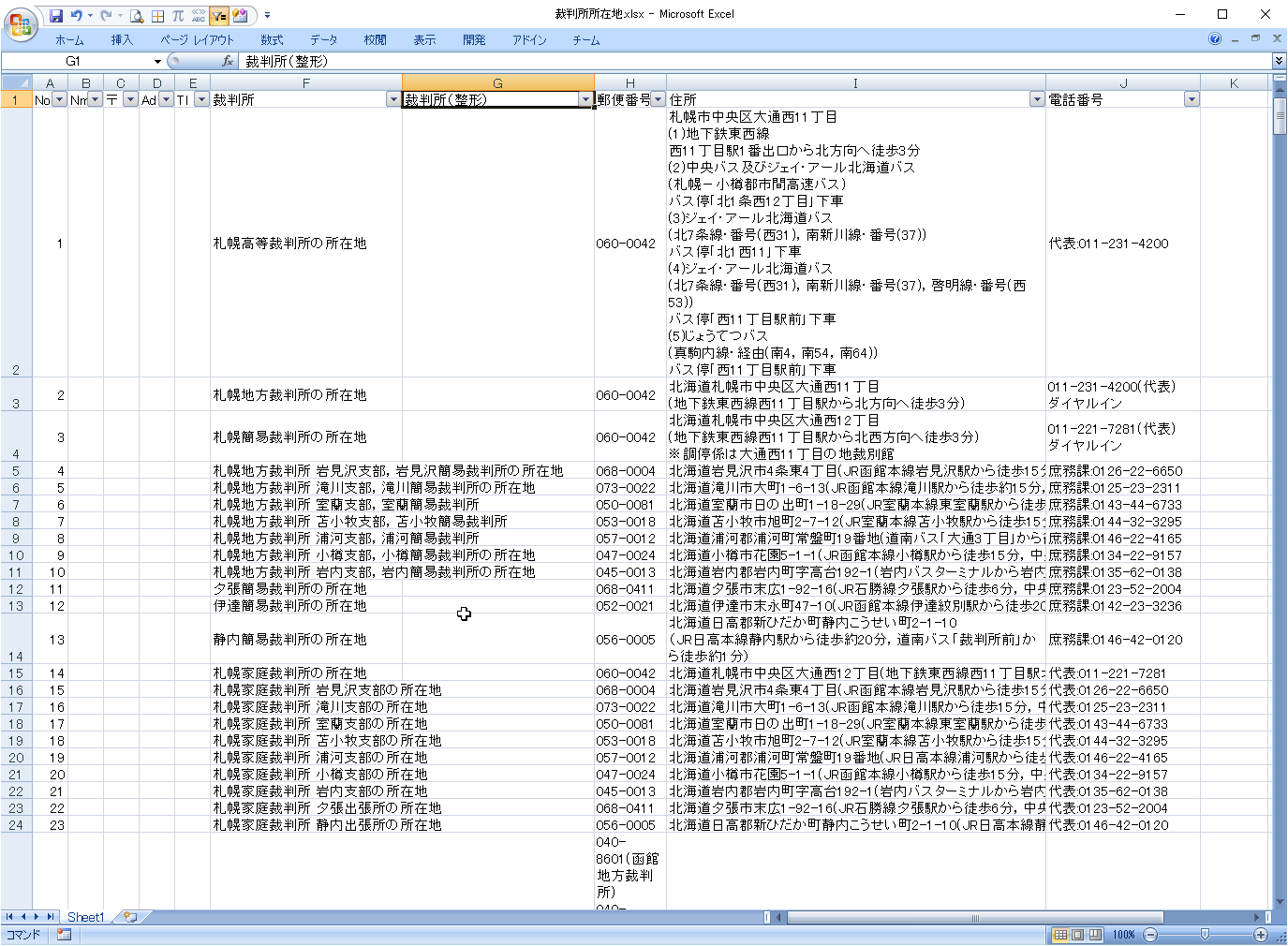
少し複雑ですが、セルG2に以下の数式を入力します。
=IF(ISERR(SEARCH("の所在地",F2)),F2,LEFT(F2,SEARCH("の所在地",F2)-1))セルF2の値:「札幌高等裁判所の所在地」
- セルF2に「の所在地」が含まれる場合
SEARCH関数で「の所在地」の文字位置(=8)を取得する(ISERRはFALSE)
LEFT関数で7文字目までを切り取る - セルF2に「の所在地」が含まれない場合
SEARCH関数が#VALUE!を返し、エラーとなる。
ISERR関数が、ISERR(#VALUE!)となり、TRUEを返す。
IF関数の条件がTRUEなので、F2の値をそのまま返す。
最終行までコピーします。

標準外データの抽出
G列の内容をフィルターで確認します。
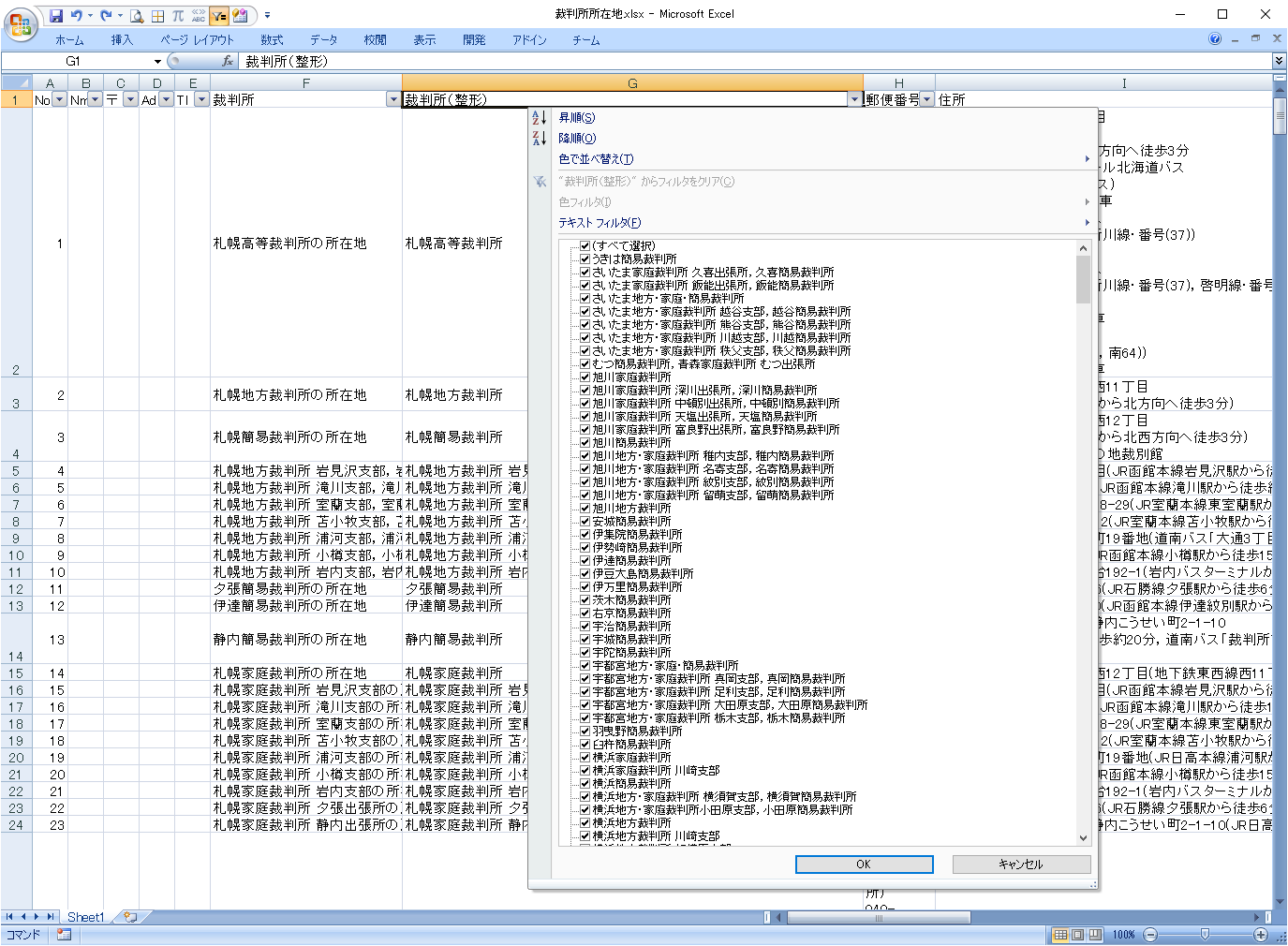
目視するしか方法がありません。
1ヵ所(※)が記載されています。
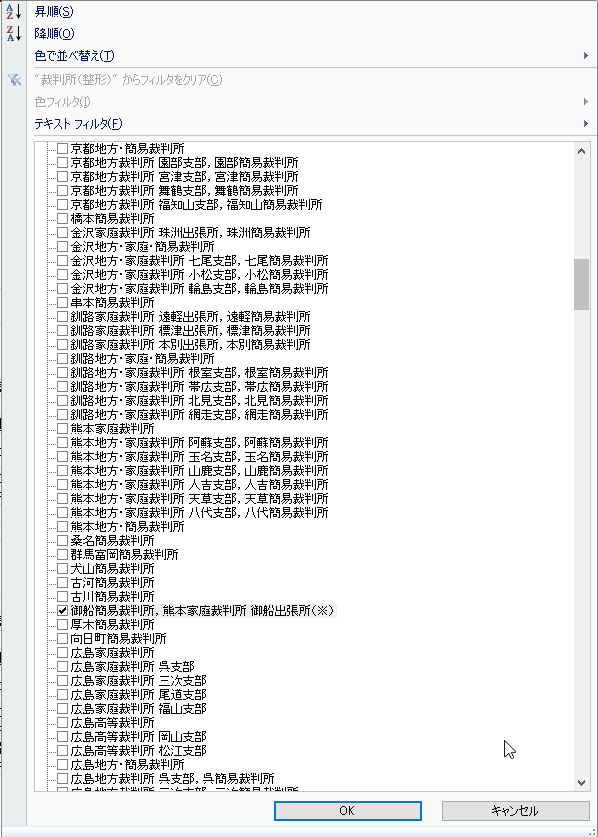
データを抽出して、B列の分類欄に「1」を記入しておきます。

郵便番号
不要文言の削除
郵便番号のフィルターをクリックして、リストを表示します。
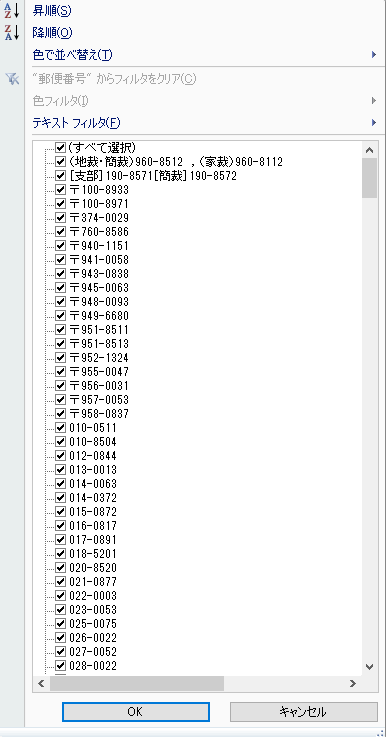
郵便番号が2個以上あるものがありますが、いったん無視して、『〒』が入っているものがあります。
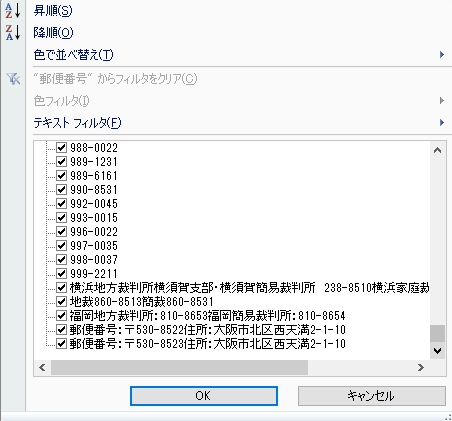
後ろの方に、『郵便番号:〒』が入っているものがあります。住所情報も含んでいて、あわせて対応が必要なので、いったん無視します。
Excel置換
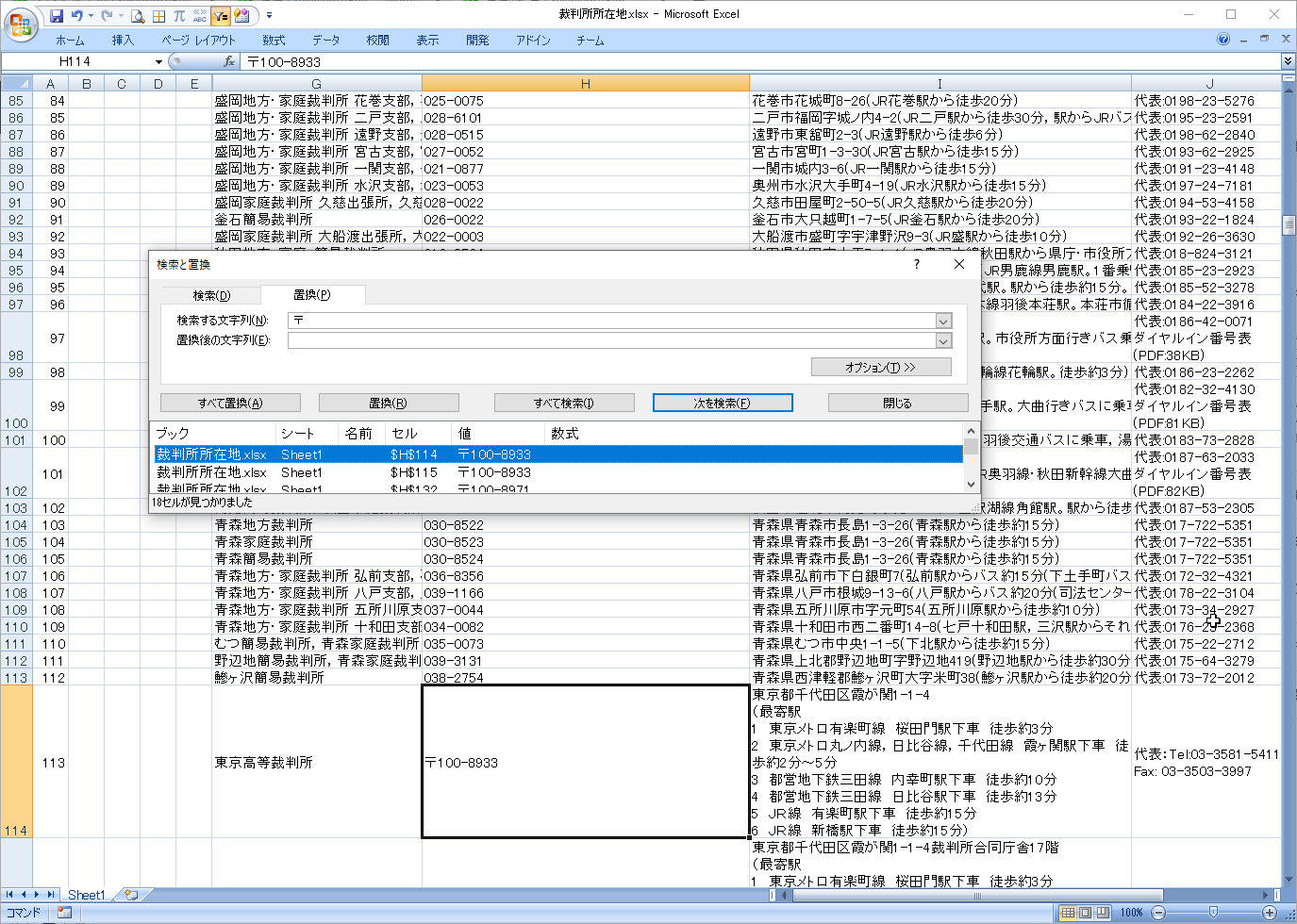
『〒』を取り除きます。
標準外データの抽出
郵便番号を降順に並べ替えます。
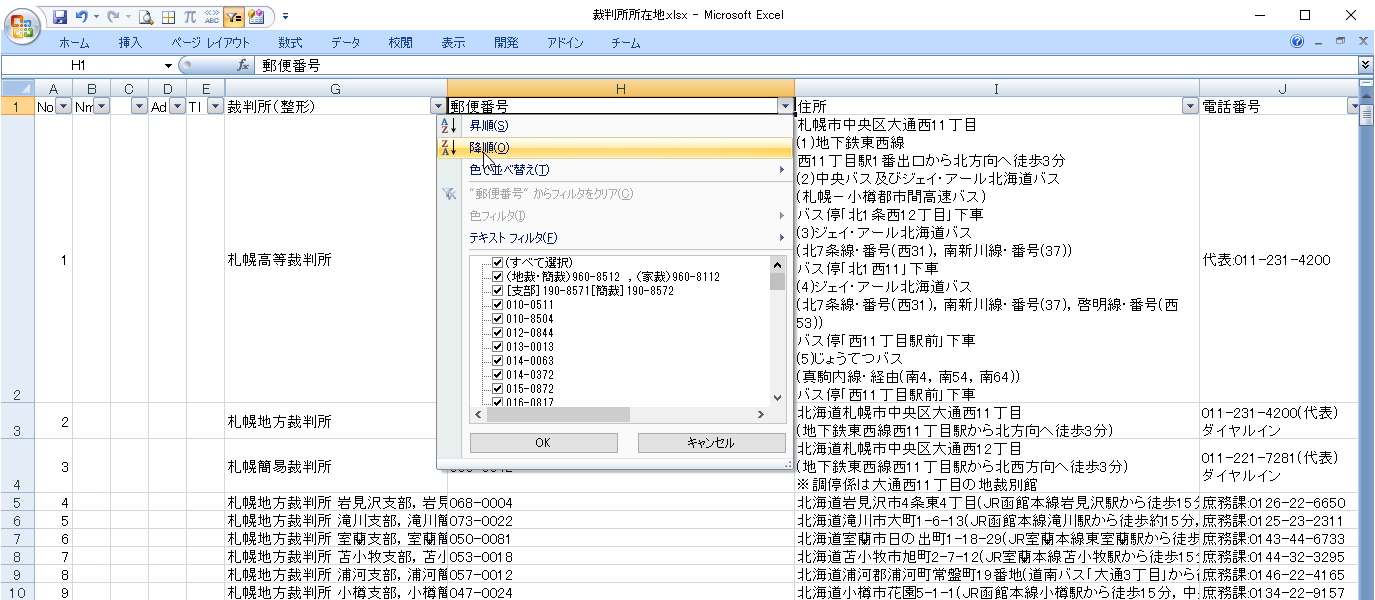
郵便番号が2個入っているデータがあります。
C列の分類欄に「1」を記入します。
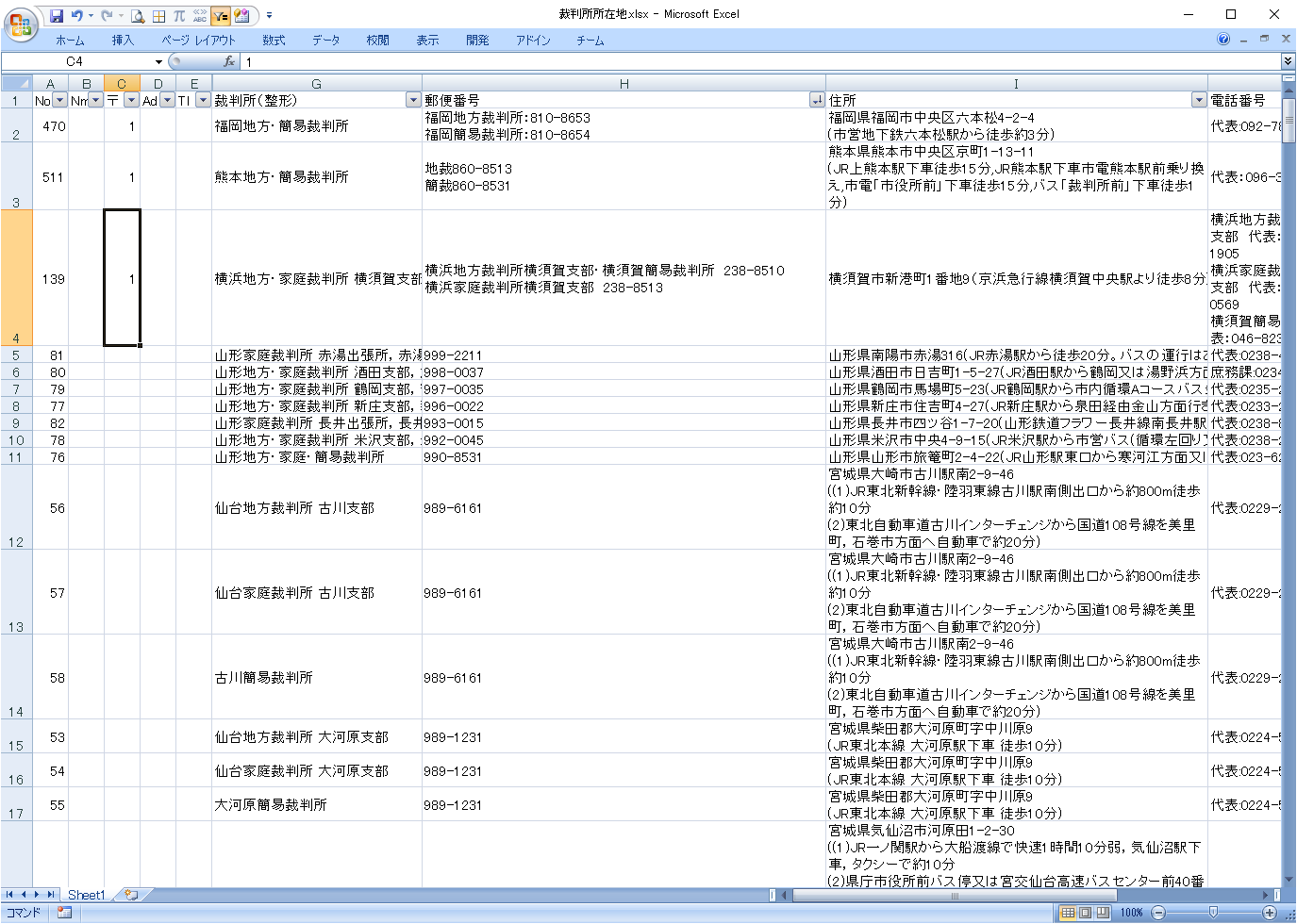
住所まで一緒に記載されています。C列に「1」を記入します。

最終行も標準外データですので、「1」を記入します。
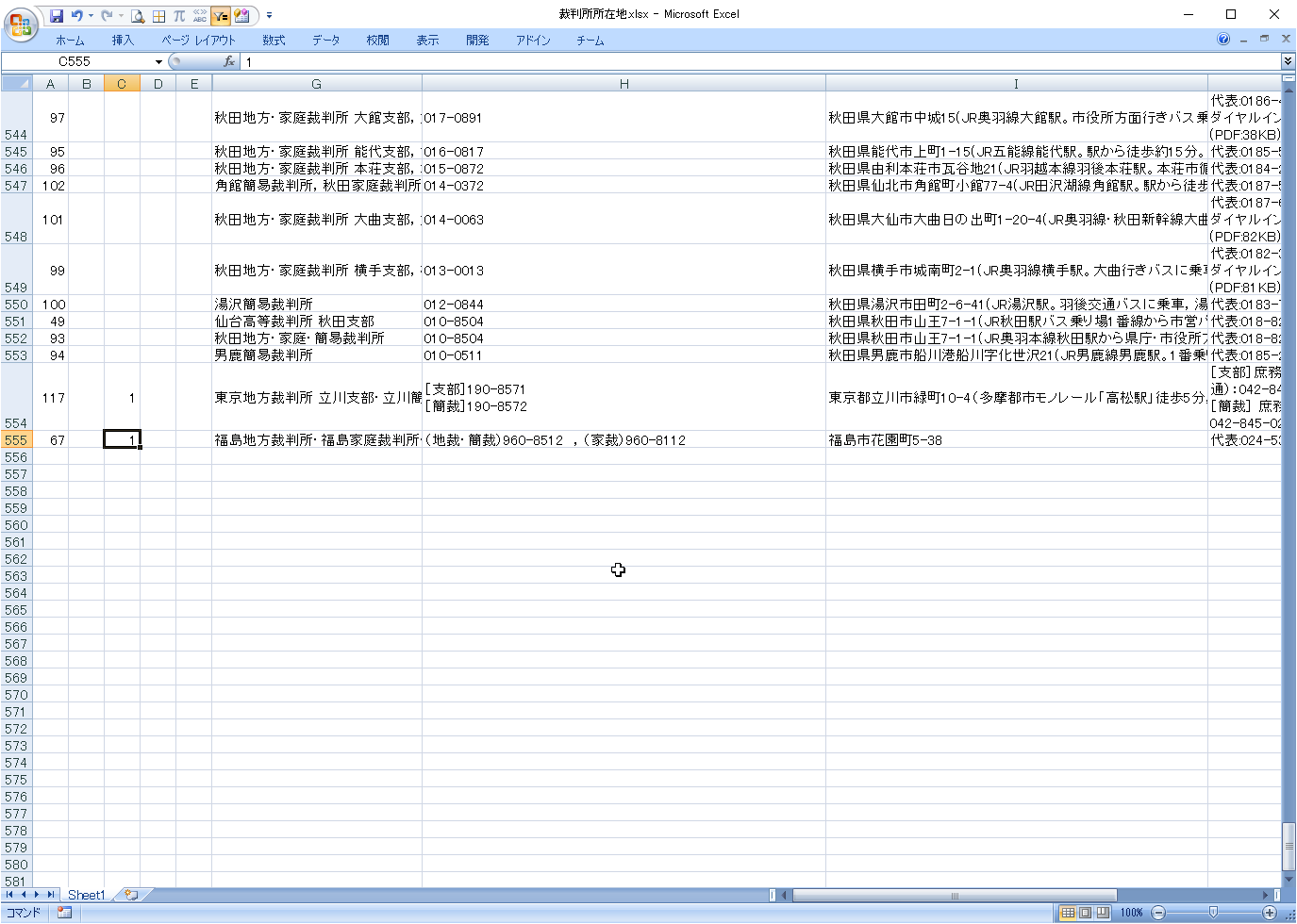
それ以外の標準外データをフィルタで検出します。
まず、C列のフィルタで、すでに抽出済み(値が1のもの)を除外します。

その中かから、目視で標準外データを抽出します。

よく見ると、ハイフンでなく長音のものがありますが、いったん無視します。
抽出したデータのC列に「1」を記入します。
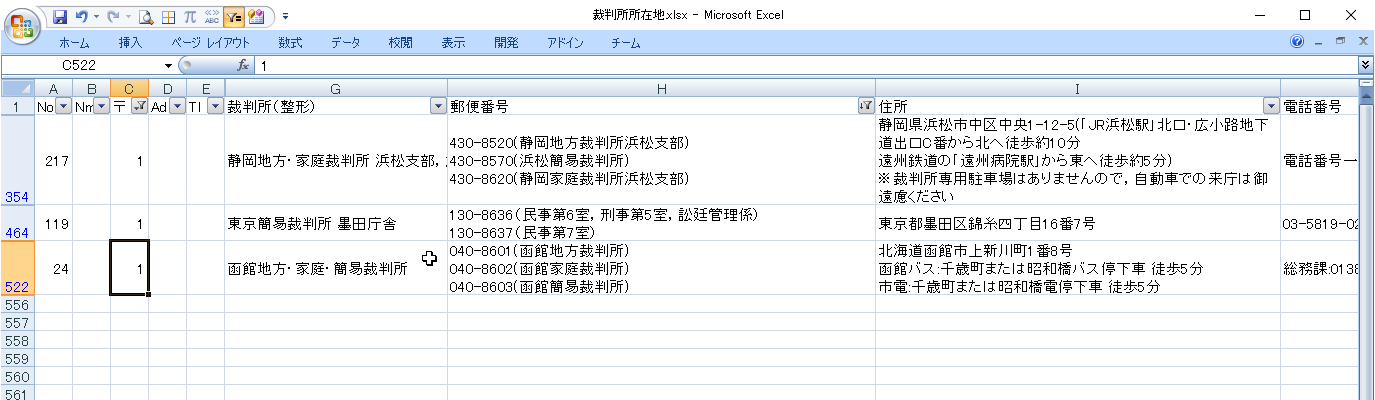
標準外データ(完成)
郵便番号のフィルタを元に戻します。

C列が「1」のデータを抽出します。
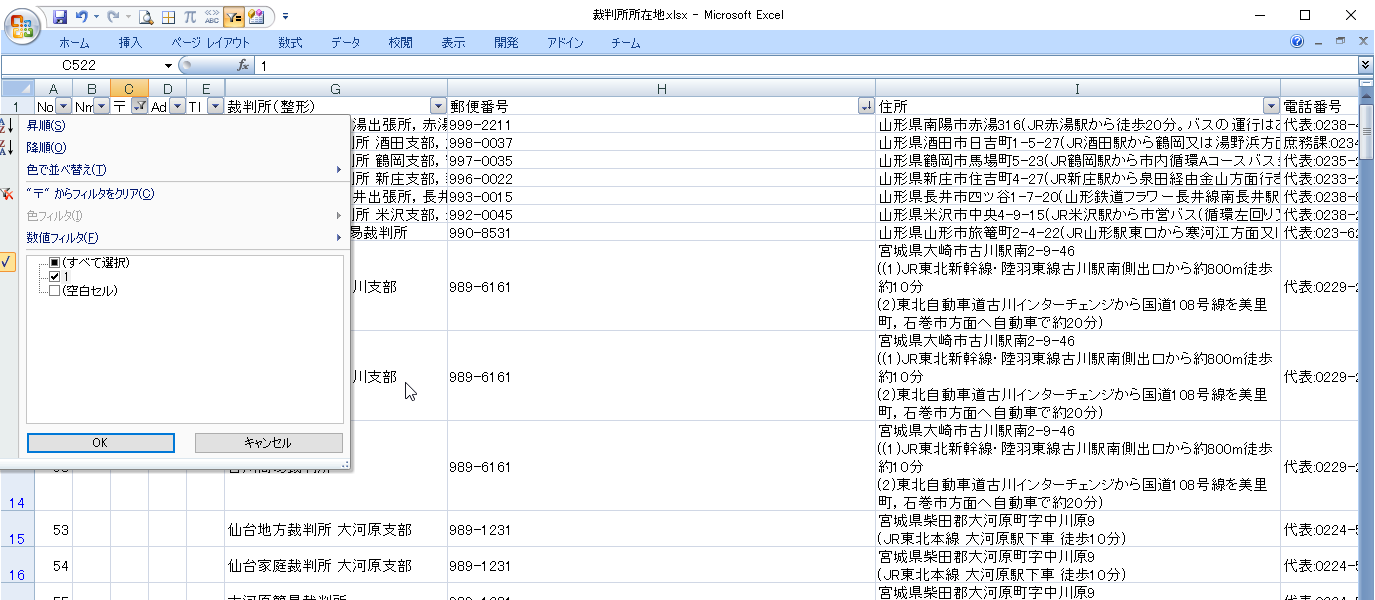
これら10件について、後ほど処置を考えます。
.png)
住所
ここで、そろそろウィンドウ枠の固定をしておきます。
2行目を選択して、「ウィンドウ枠の固定」

不要データの分割
住所データを見ると、「住所」と「アクセス方法」に分かれています。
見たところ区切りは、改行の場合と『(』の場合があります。

ひとまず、改行、または『(』で住所データを分割することにします。
まず、分割した住所を表示する列(住所1、住所2)を追加します。
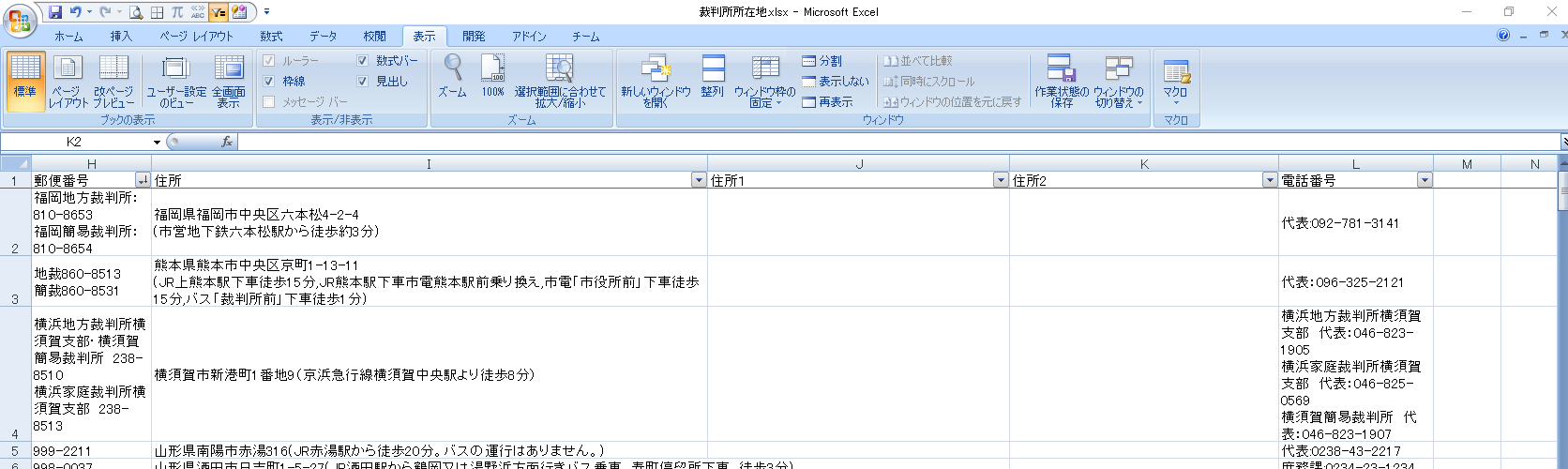
セルJ2に以下の数式を入力します。
=IF(MIN(IFERROR(SEARCH("(",I2),999),IFERROR(SEARCH("(",I2),999),IFERROR(SEARCH(CHAR(10),I2),999))=999,I2,LEFT(I2,MIN(IFERROR(SEARCH("(",I2),999),IFERROR(SEARCH("(",I2),999),IFERROR(SEARCH(CHAR(10),I2),999))-1))やりたいこと
セルI2に、半角カッコ・全角カッコ・改行のいずれかが含まれる場合、そのうち最初に現れる文字位置でI2を先頭から切り出す。
文字検索
- I2に半角カッコが含まれる
SEARCH(“(“,I2) - I2に全角カッコが含まれる
SEARCH(“(",I2) - I2に改行が含まれる
改行はCHAR(10)で表現します。
SEARCH(CHAR(10),I2)
SEARCH関数の戻り値
- SEARCHでヒットした場合
ヒットした文字の位置を返す - SEARCHでヒットしなかった場合
エラー(#VALUE!)を返す。
3つのうちどれかが最初に現れる位置を取得するには?
- 3つともヒットした場合は、3つのうち最小の数を採用すればよい。
→MIN関数を用いる - 3つのうち、どれかがヒットしない場合は、#VALUE!を大きな数値(=999)に変更する。
→3つのうち、ヒットした部分は999より小さな数になるので、MIN関数でヒットした位置が取れる。 - 3つともヒットしない場合は999が返ってくる。
ここまでの数式
MIN(IFERROR(SEARCH("(",I2),999),IFERROR(SEARCH("(",I2),999),IFERROR(SEARCH(CHAR(10),I2),999))この数式の結果が、
- 999の場合
検索にヒットしなかったので、I2の値をそのまま表示 - 999以外の場合
検索にヒットしたので、3つのうち最初にヒットした文字位置が返ってくる。
よって、LEFT関数でI2から、MIN関数の結果マイナス1字までを切り出す。
IF(MIN関数の結果=999,I2,LEFT(I2,MIN関数の結果-1))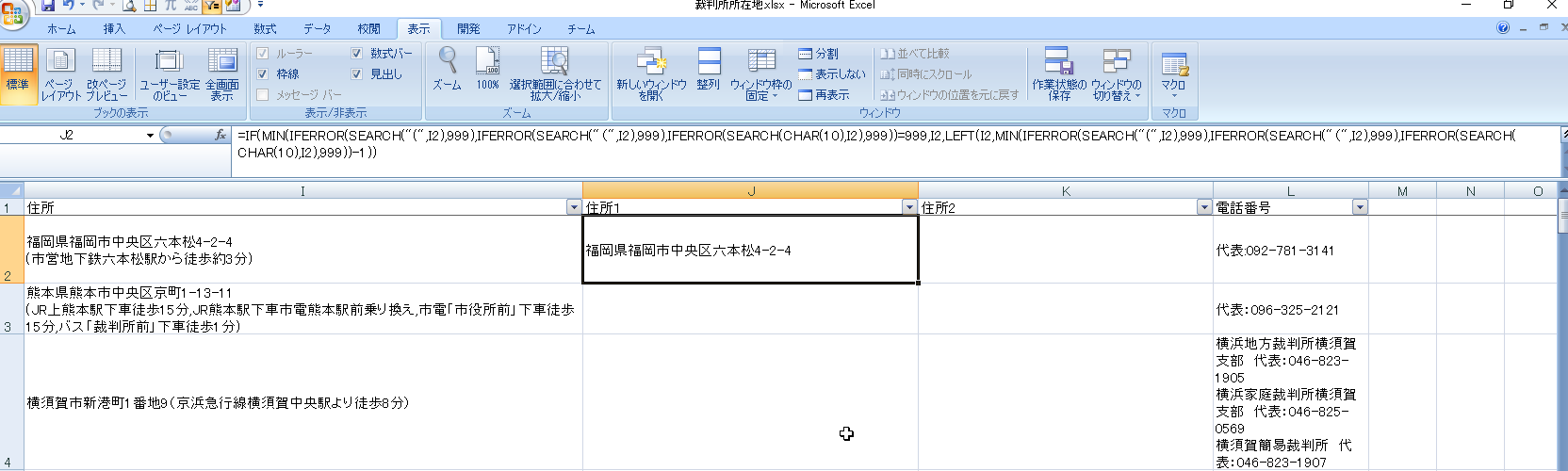
次に、元の文字列(セルI2)から、切り出した文字列(セルJ2)を除くため、I2からJ2の内容を空文字に置き換えます。
セルK2に以下の数式を入力します。
=SUBSTITUTE(I2,J2,"")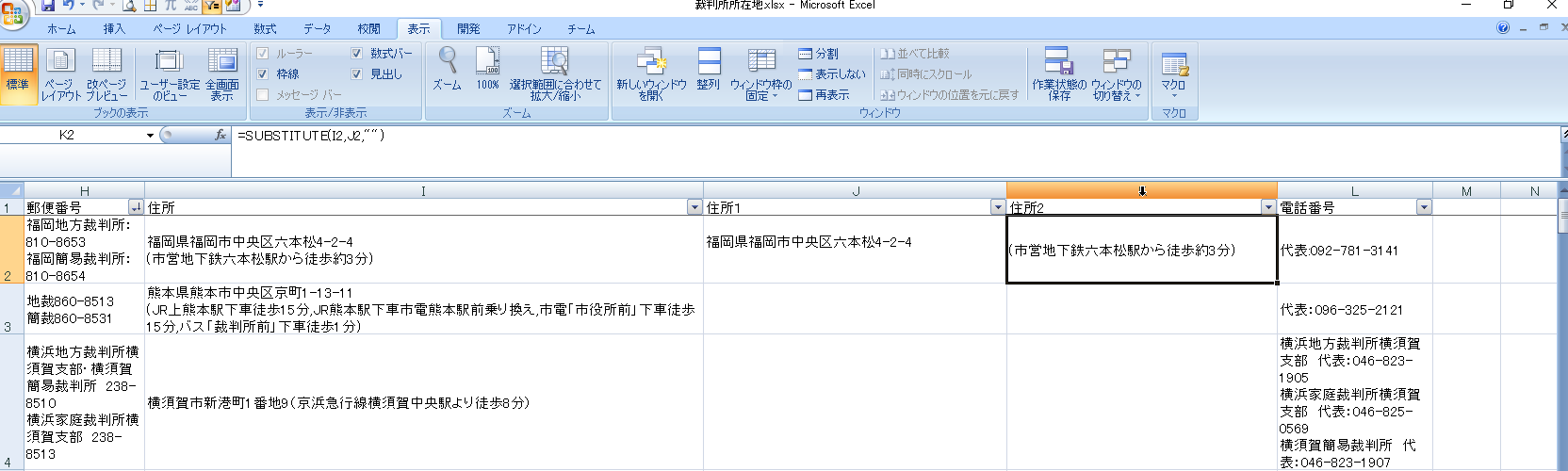
最終行までコピーします。

標準外データの抽出
住所1のフィルタをクリックします。
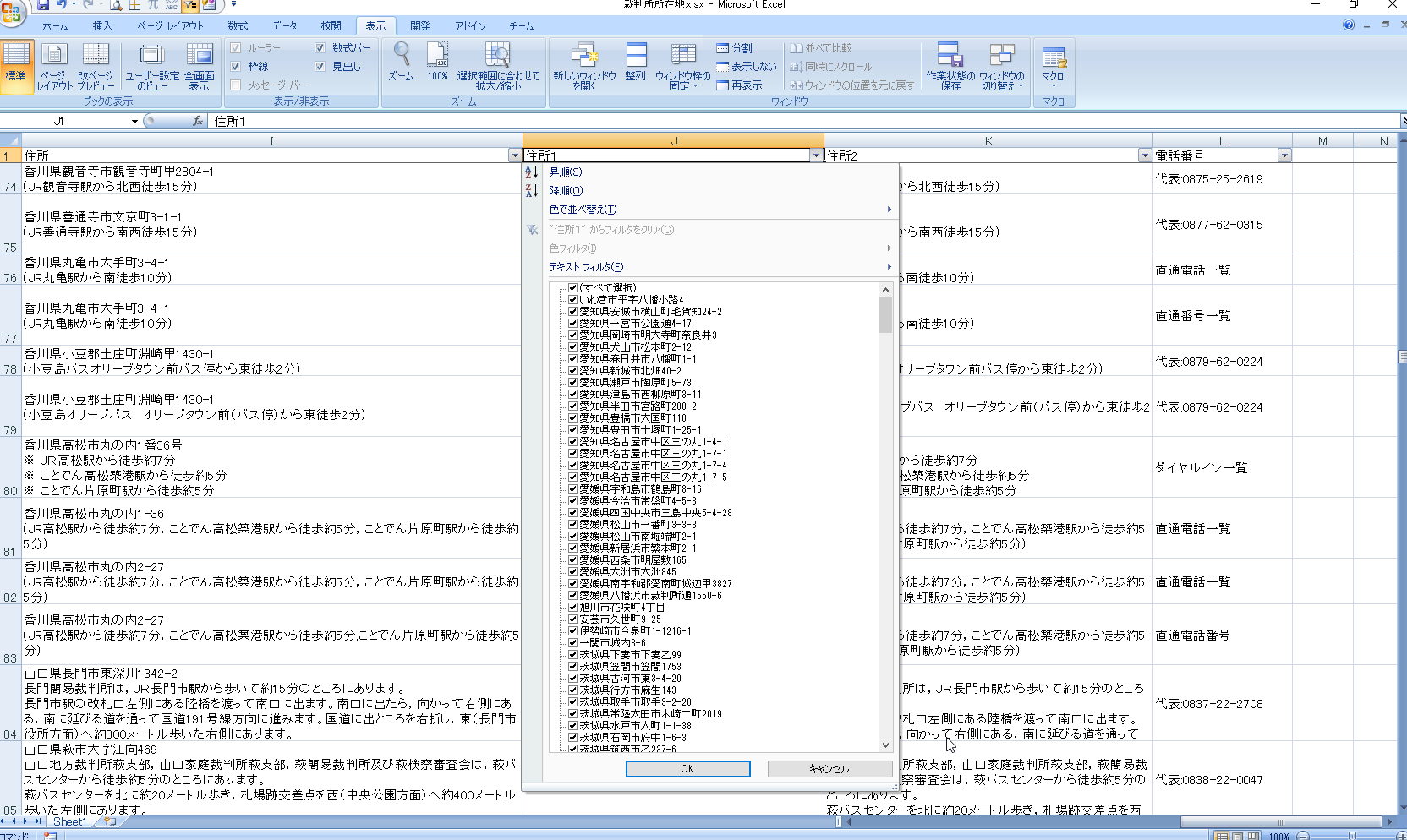
数が多いので大変ですが、よく見ると電話番号が紛れています。
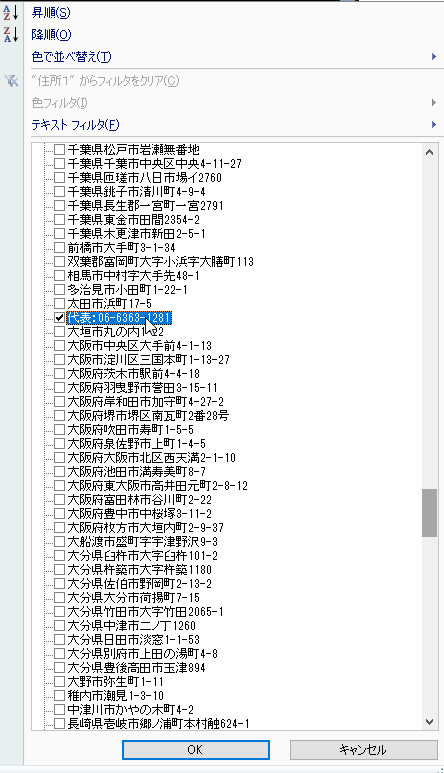
郵便番号でもチェック済ですが、D列にも「1」を記入しておきます。
住所2のフィルタをクリックします。
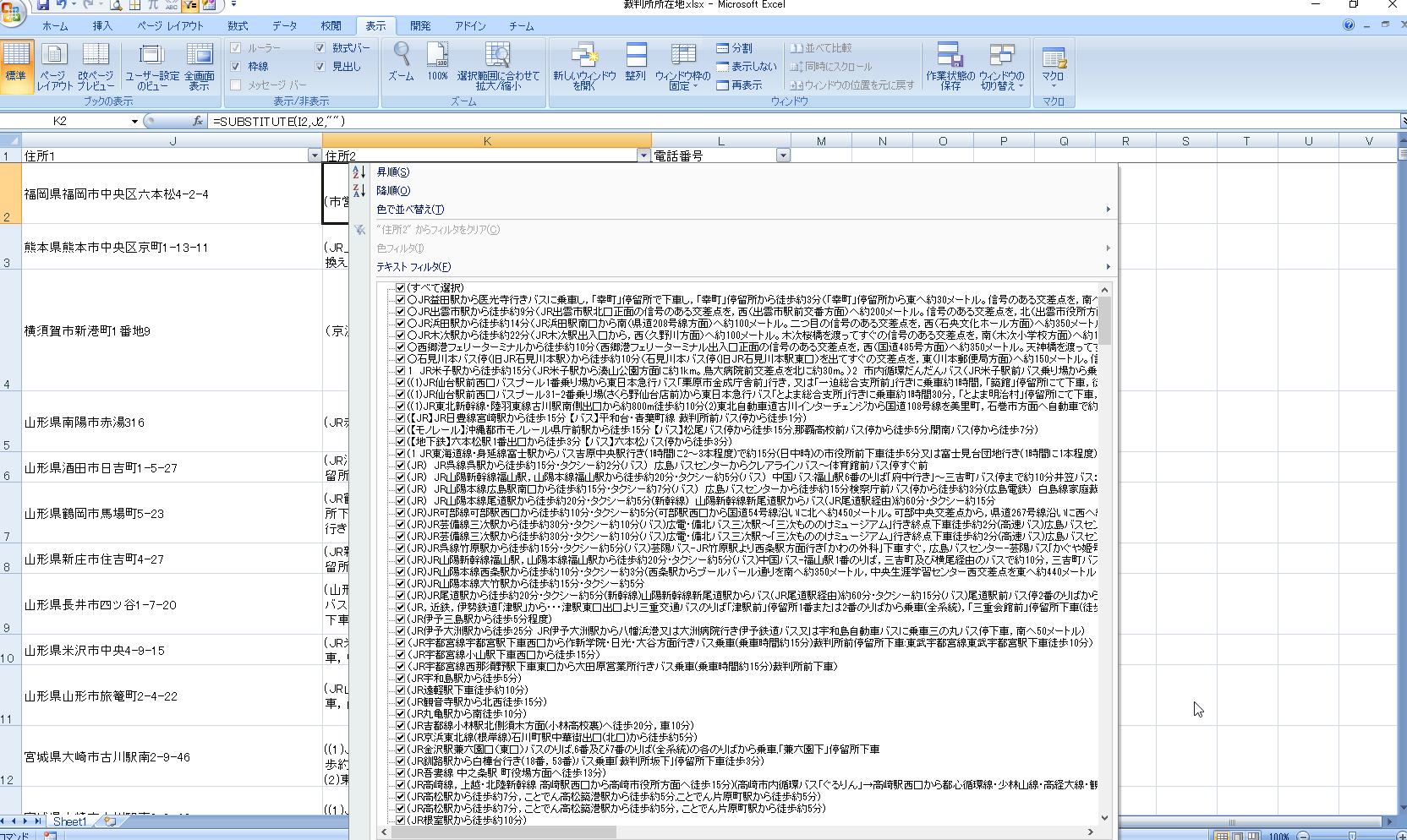
カッコなどの記号がない行に、本来の住所データが含まれている可能性を考えましたが、大丈夫のようです。
電話番号
標準外データの抽出
フィルタをクリックして、まず降順に並べ替えます。
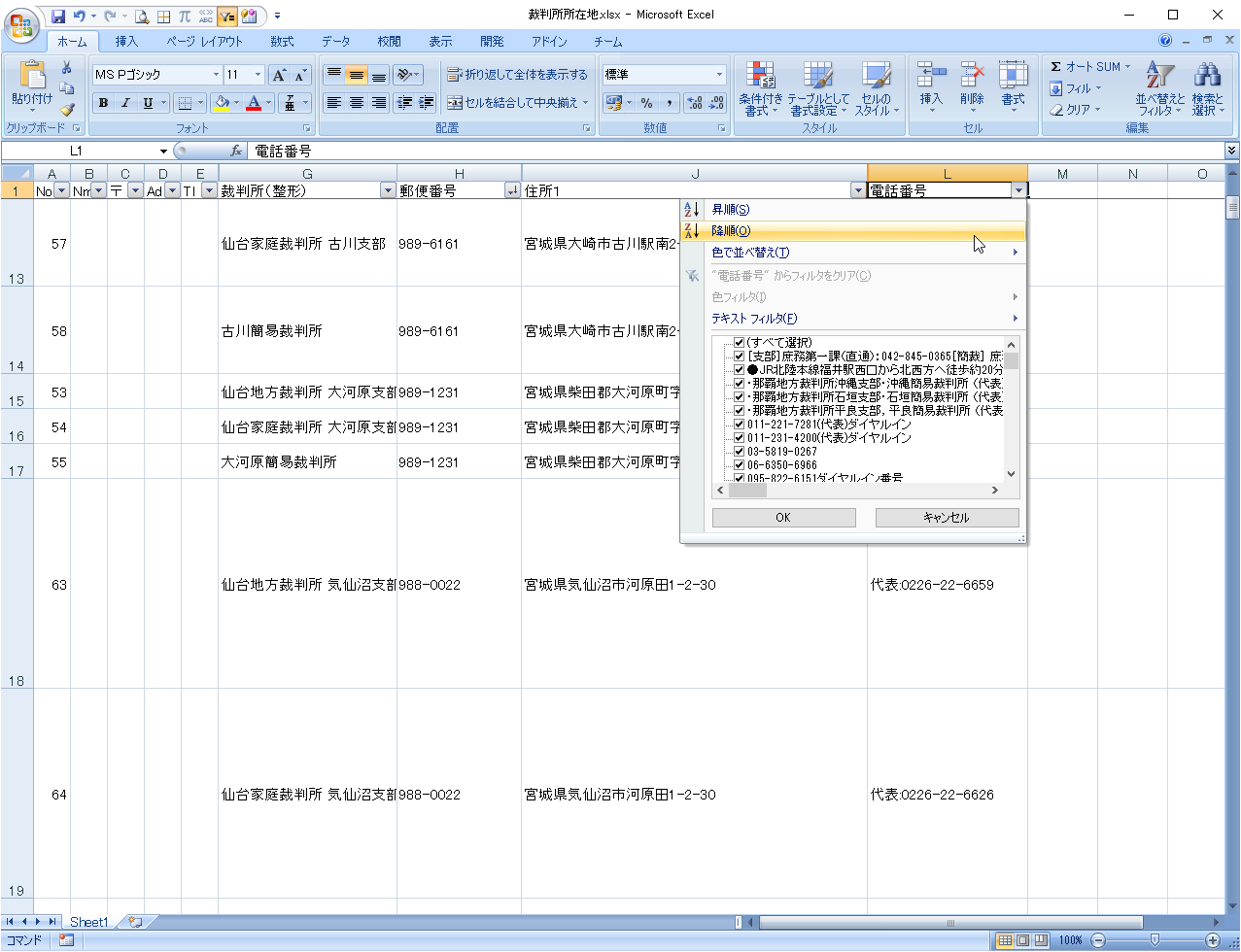
電話番号を取得できていない行に対し、E列に「N(None)」を記入します。
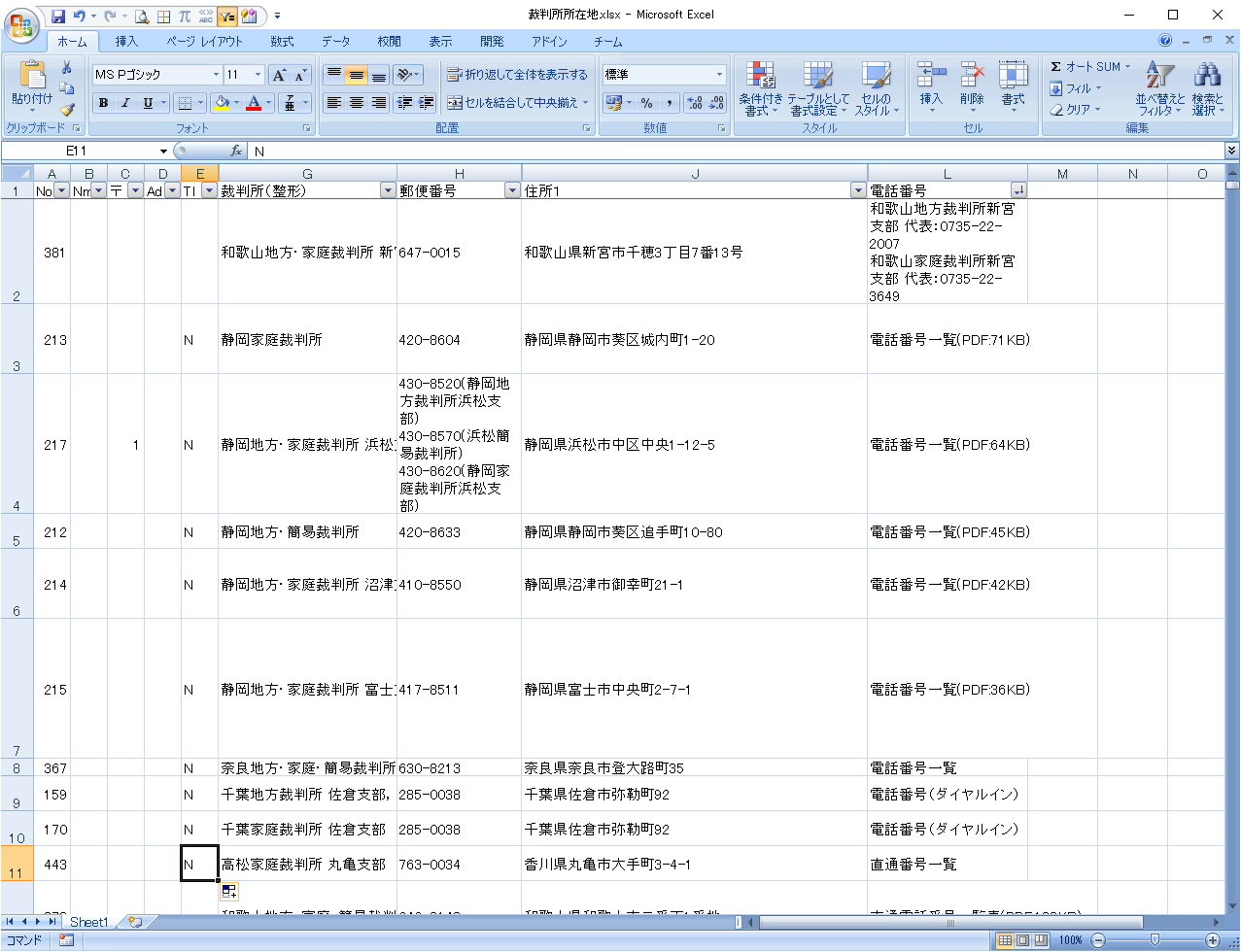
電話番号が2件以上入力されている行に対し、E列に「D(Double)」を記入します。
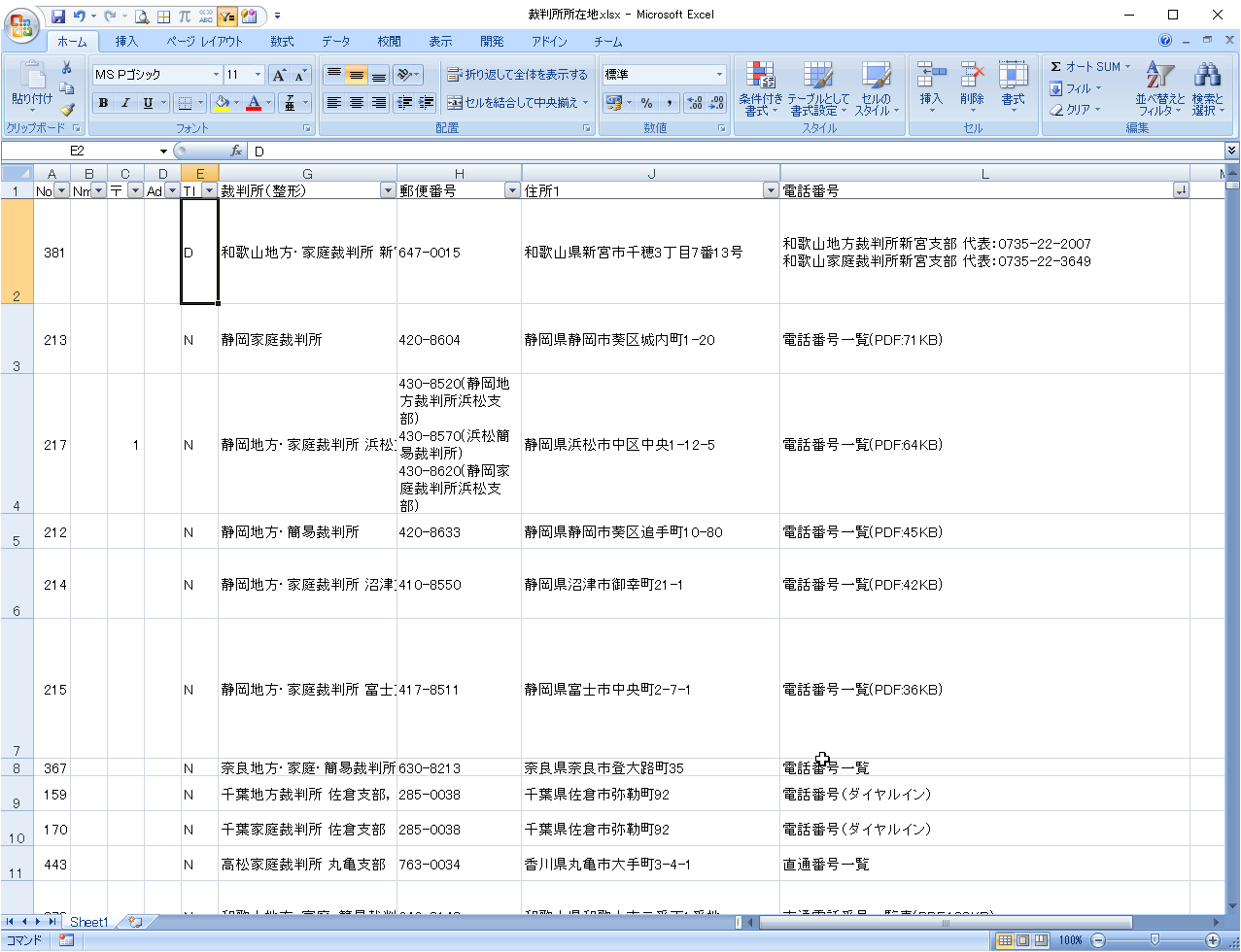
最後の大阪のデータはE列に「1」を記入します。

電話番号なし
E列のフィルタで「N(電話番号なし)」を抽出します。

「さいたま」の電話番号欄にアクセス方法が記載されています。
もとのWebページで、アクセス方法のさらに下に、電話番号が記載されている可能性があります。
「さいたま地裁」のページを確認します。
予想通り、アクセス方法の下に電話番号欄がありました。しかし「ダイヤルイン一覧」とあり、電話番号の取得はできません。よってE列は「N」のままです。
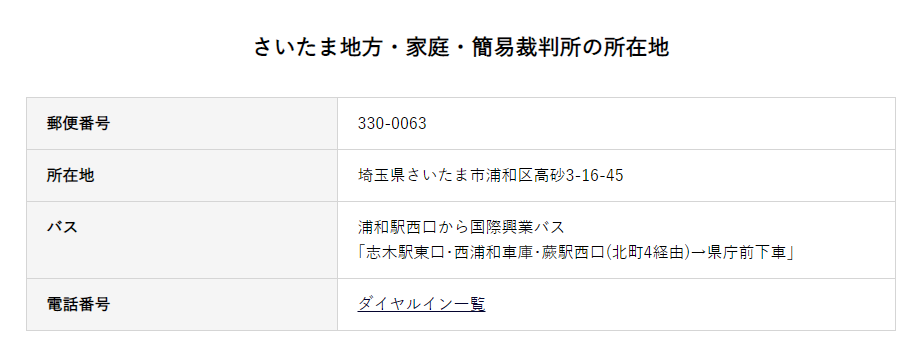
同様に福井のデータを調べます。
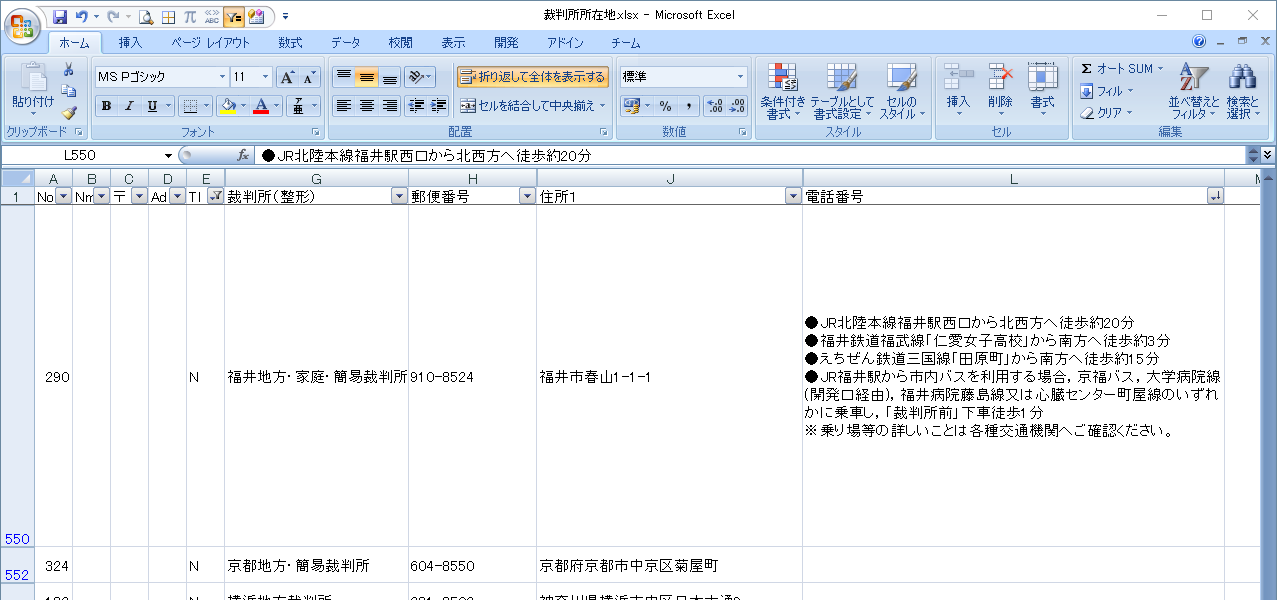
こちらも「各係直通の電話番号」とあり取得できませんので、E列は「N」のままです。
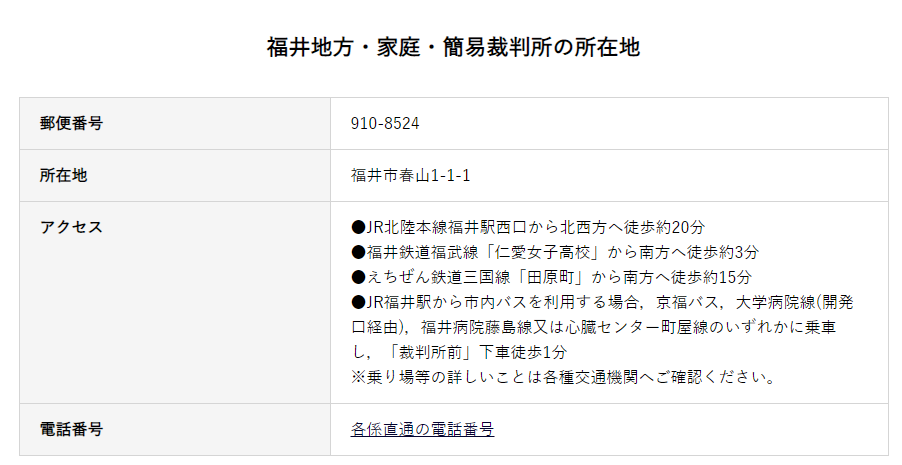
電話番号2件以上
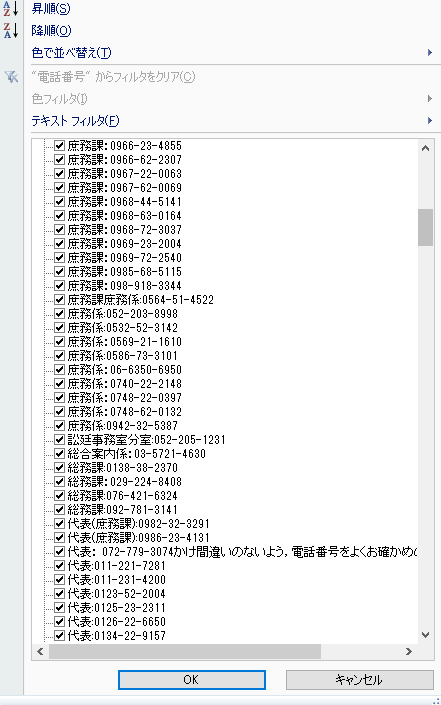
続いてE列を「D(2件以上)」でフィルタリングします。
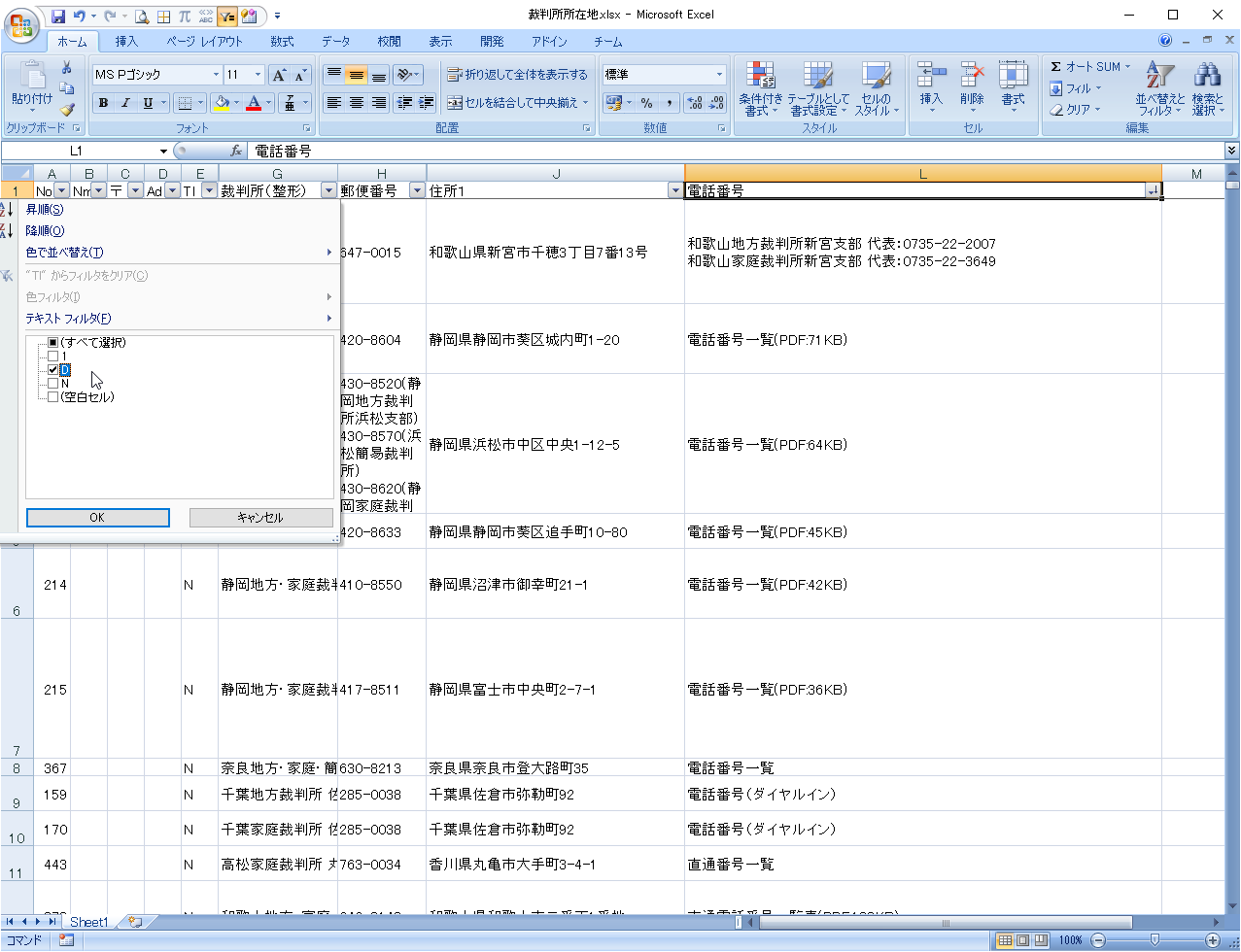
こちらは問題なさそうです。
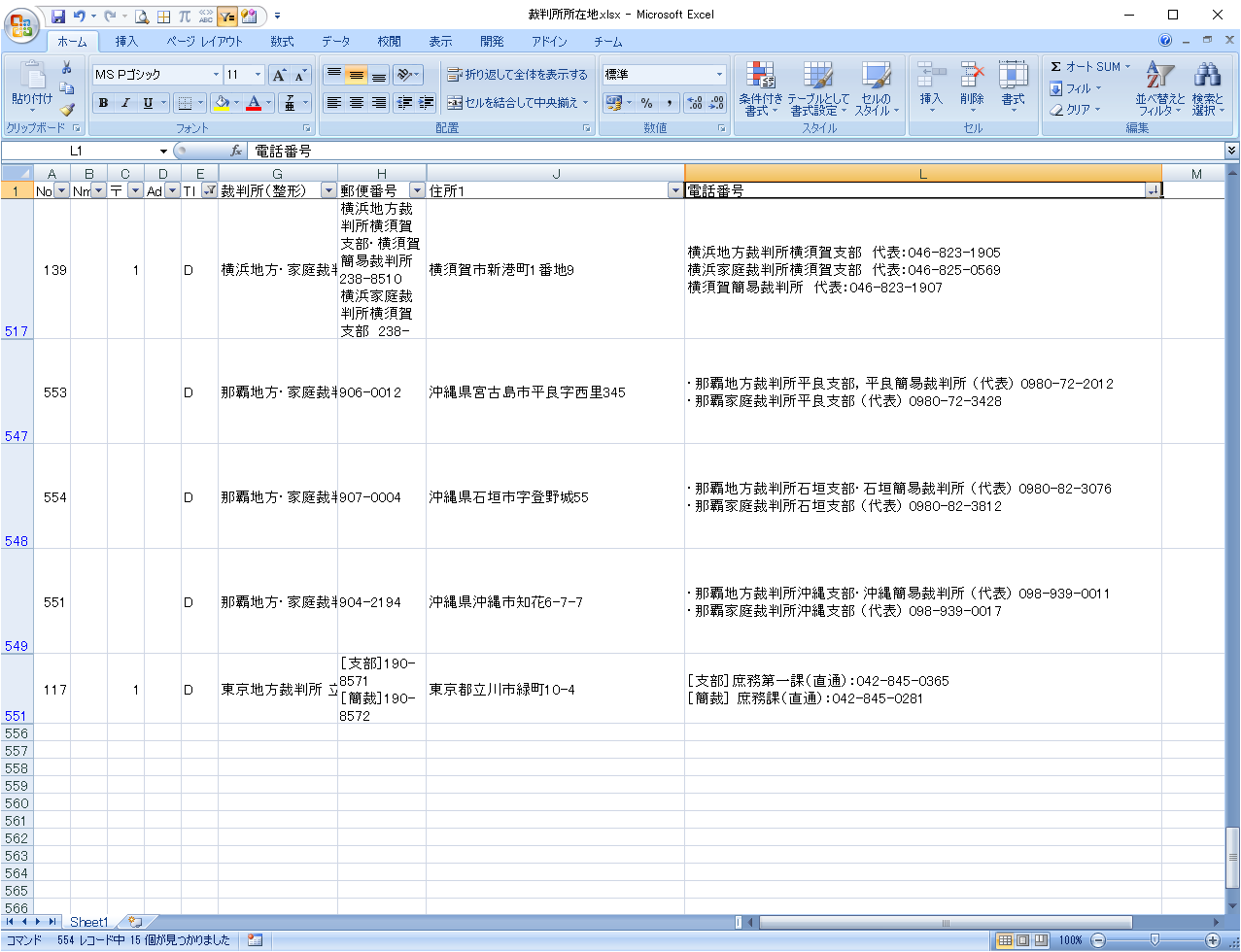
不要データの分割
フィルタでE列が空白のデータを抽出します。

左側の分割
データの内容を見たところ、「:(コロン)」(全角/半角)で区切ることができそうです。

右側の分割
一方、電話番号の後に、窓口情報や注意書きが記載されているケースがあります。
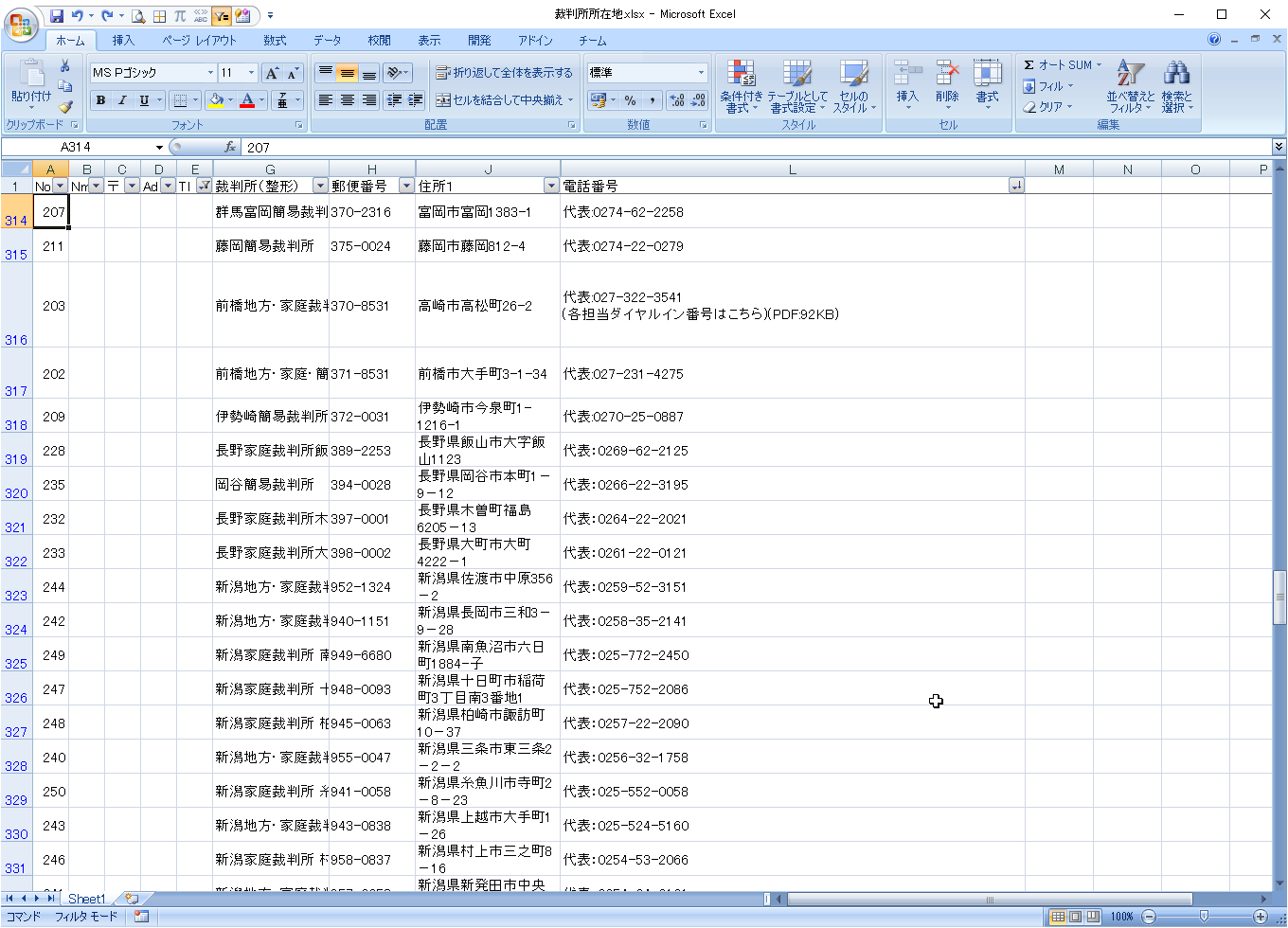
改行とカッコで区切ることができそうです。
ただし下のように「代表(庶務課):」というデータがありますので、カッコで区切る場合は、カッコが数字の右側にある場合に区切ります。
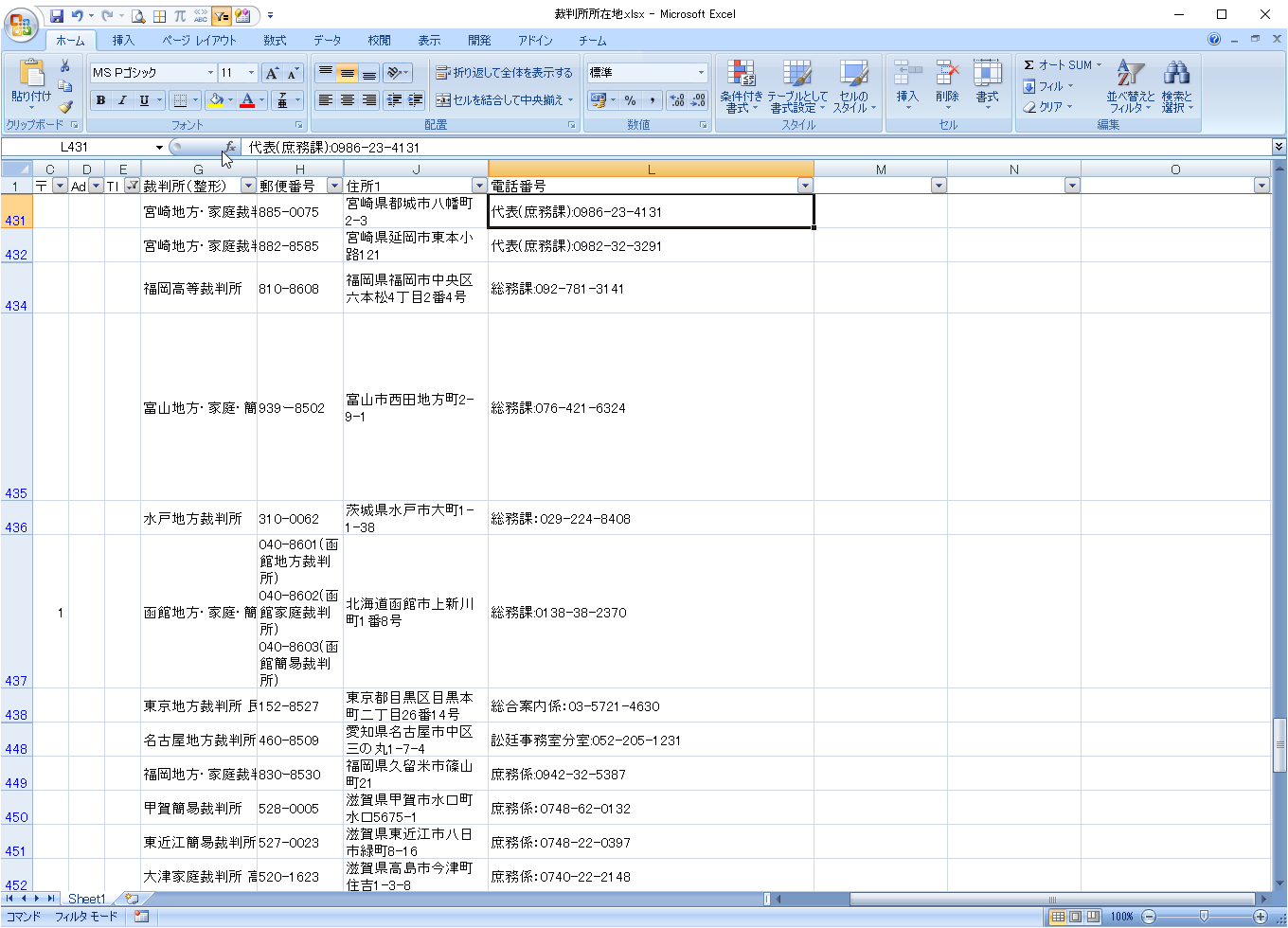
数式の入力
分割したデータを表示するために、M~O列を追加します。
(窓口、番号、注意書き)
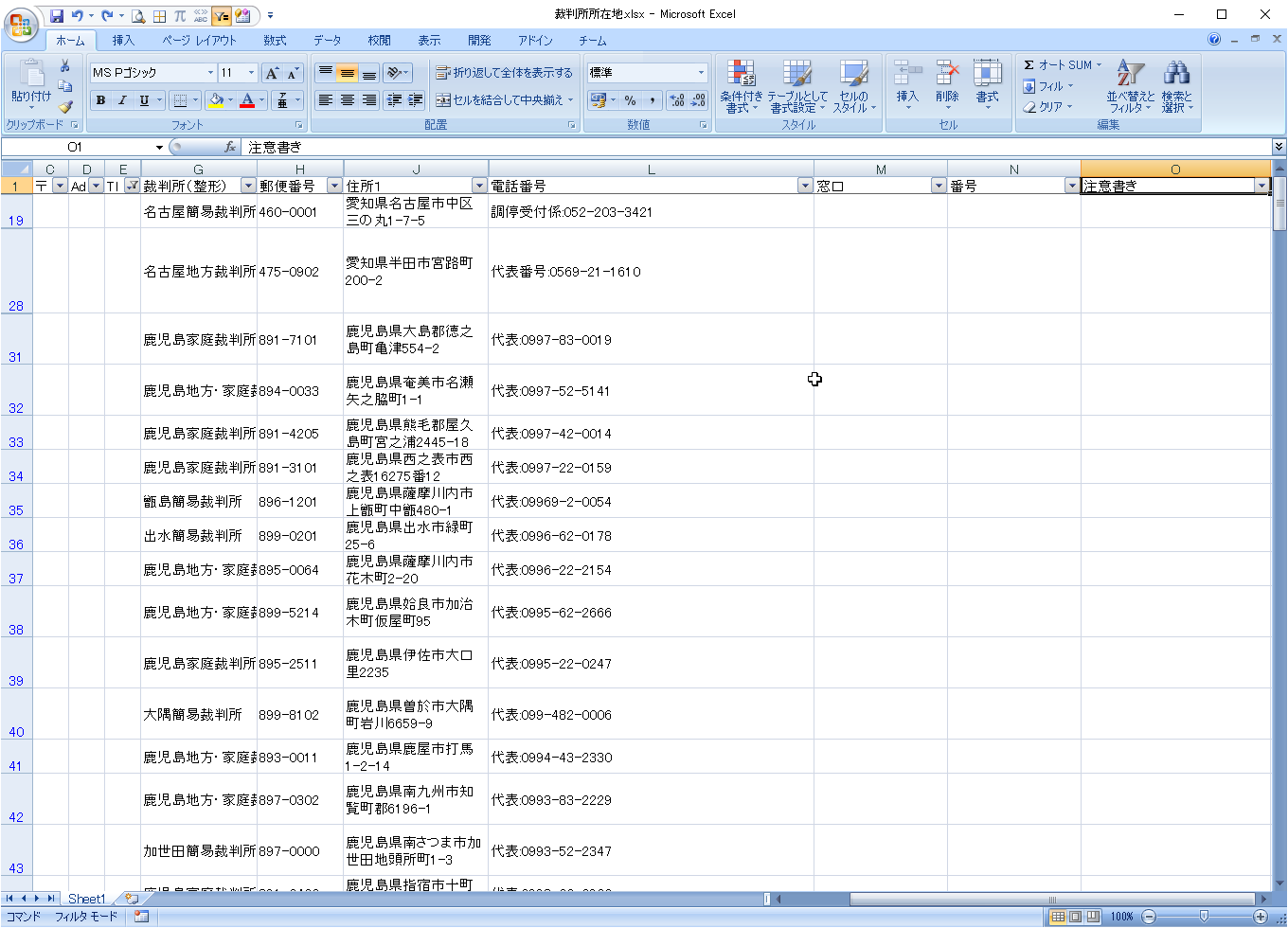
左側の区分け
セルM19に以下の数式を入力します。
=IF(E19="",LEFT(L19,MAX(IFERROR(SEARCH(":",L19),0),IFERROR(SEARCH(":",L19),0))),"")- 最初のIF文で、E列が空白(電話番号が1件)のデータを対象とします。
- MAX関数は
- L列に「:(半角)」または「:(全角)」が含まれる場合
どちらか大きい方の文字位置を返します。 - L列に検索文字が含まれない場合
IFERROR関数で0を返すようにします。
- L列に「:(半角)」または「:(全角)」が含まれる場合
- LEFT関数は
- 検索文字がある場合は、文字位置まで切り出します。
- 検索文字がない場合は、MAX関数の戻り値は0なので、何も出力しません。
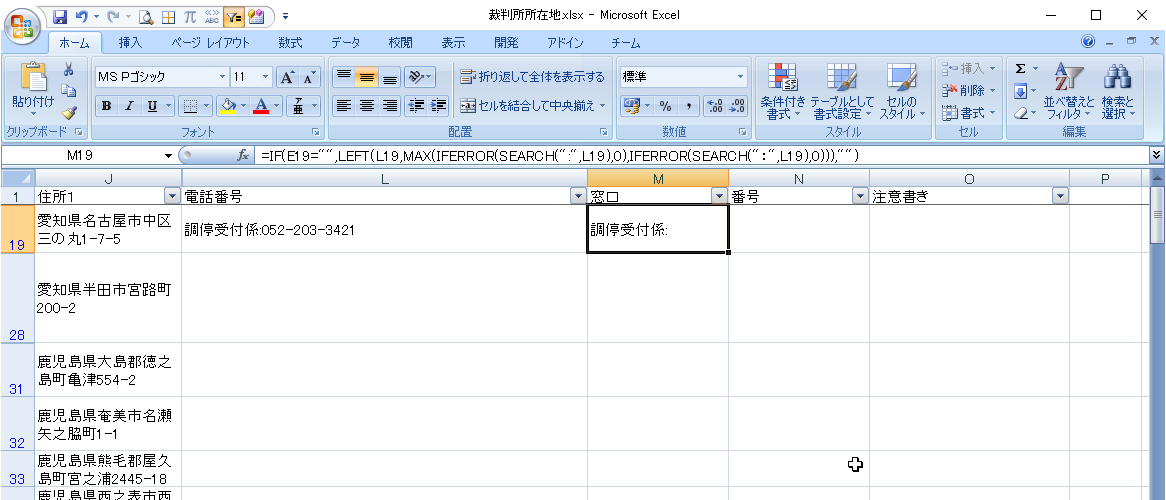
右側の区分け

セルN19に以下の数式を入力します。
=IF(E19="",IF(MIN(IFERROR(SEARCH("(",SUBSTITUTE(L19,M19,"")),999),IFERROR(SEARCH("(",SUBSTITUTE(L19,M19,"")),999),IFERROR(SEARCH(CHAR(10),SUBSTITUTE(L19,M19,"")),999))=999,SUBSTITUTE(L19,M19,""),LEFT(SUBSTITUTE(L19,M19,""),MIN(IFERROR(SEARCH("(",SUBSTITUTE(L19,M19,"")),999),IFERROR(SEARCH("(",SUBSTITUTE(L19,M19,"")),999),IFERROR(SEARCH(CHAR(10),SUBSTITUTE(L19,M19,"")),999))-1)),"")- IF文の中身は住所データの分割の応用です。
- セルL19に、半角カッコ・全角カッコ・改行のいずれかが含まれる場合、そのうち最初に現れる文字位置で先頭から切りだします。
- ただし数字の左側部分は、すでにM列で切り出していますので、切り出し対象文字列はL19からM19をあらかじめ取り除いた値となります。
- よって、住所データではI2となっていた部分に、【SUBSTITUTE(L19,M19,"")】にて、L19からM19を取り除いた値を当てはめます。
残余分の表示
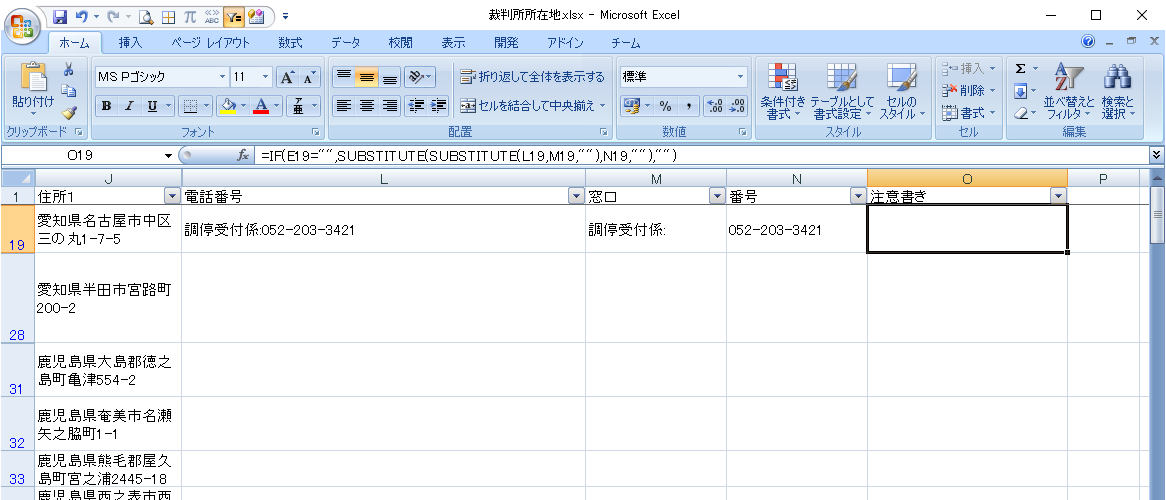
セルO19に以下の数式を入力します。
=IF(E19="",SUBSTITUTE(SUBSTITUTE(L19,M19,""),N19,""),"")
元データL19の文字列から、M19とN19の値を取り除いた、残りの部分が表示されます。
いったんフィルタを外して、2行目に数式をコピーします。
最終行まで、数式をコピーします。
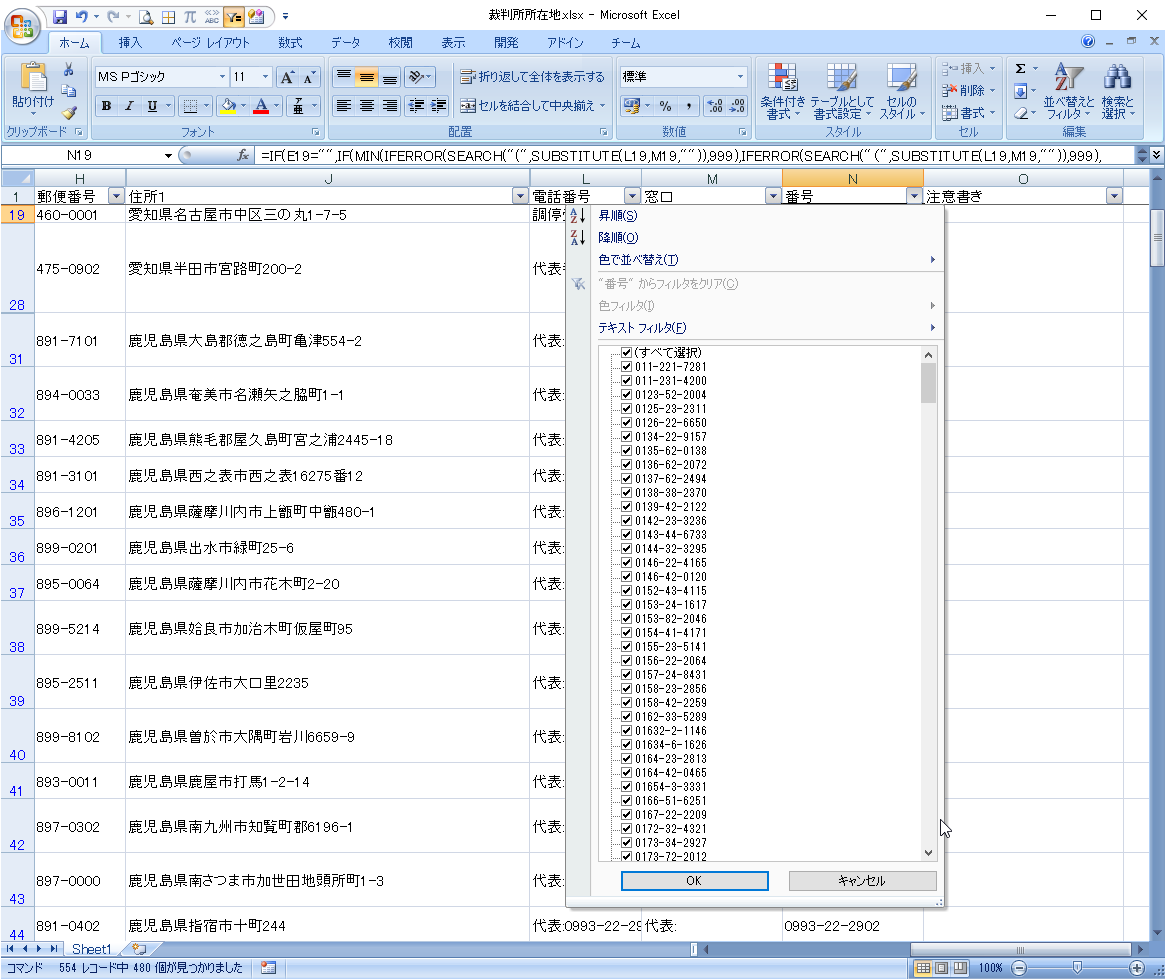
N列のフィルタをクリックして、整形したデータが番号だけであることを確認します。
まとめ
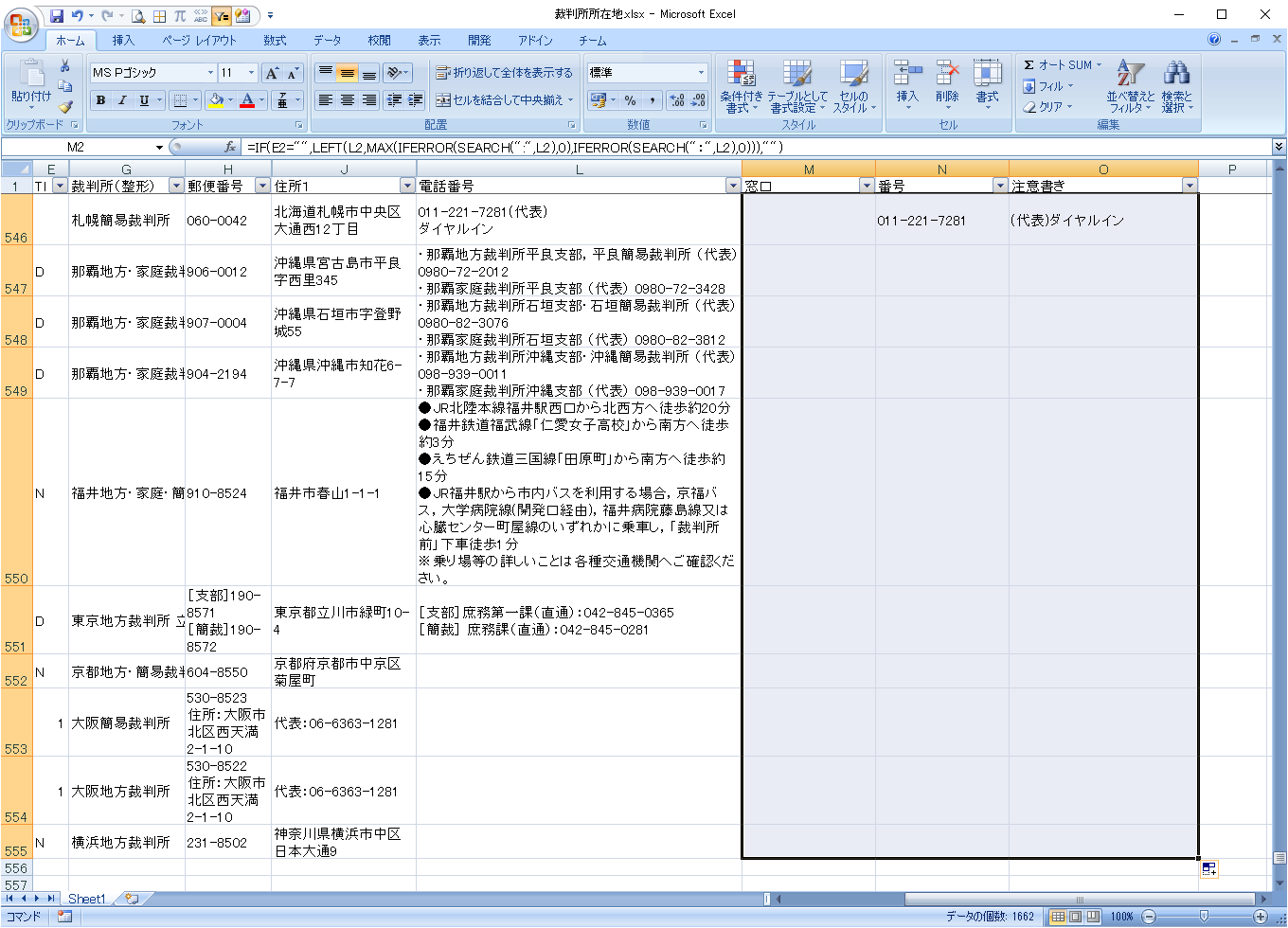
ここまでのExcelシートです。
これまでの修正内容
Excelで実施した作業は以下の通りです。
- エラーデータの削除
- 重複データの削除
- A列にNoを振る
- 分類欄の追加(B~E列)
- 裁判所名データ整形
- G列追加
- 不要文言除去(『の所在地』)
- 郵便番号
- 不要文言置換(『〒』)
- ハイフン部分が「ー(長音)」のものがあり、対応を保留中。
- 住所
- J,K列(住所1、住所2)追加
- 住所とアクセス方法を分割
- 電話番号
- M~O列(窓口、番号、注意書き)追加
- 電話番号と、それ以外の情報の分割
次回は、整形したデータ、Excelでの対応を踏まえ、全体としてどう対応するかを検討します。