Webスクレイピングで営業リストを作成する(4)
表の内容を処理に組み込んでいきます。
| No | 対象 | 内容 | 対応方針 |
|---|---|---|---|
| 1 | シート全体 | エラーデータの削除 | Excelで手動対応 |
| 2 | シート全体 | 重複データの削除 | Excelで手動対応 |
| 3 | シート全体 | A列にNoを振る | Excelで手動対応 |
| 4 | シート全体 | B列に各裁判所ページのURLを出力 | Seleniumで対応 |
| 5 | 裁判所名 | 不要文言除去『の所在地』 | Excelで手動対応 |
| 6 | 裁判所名 | 不要文言除去『(※)』 | Excelで手動対応 |
| 7 | 郵便番号 | 不要文言除去『〒』 | Excelで手動対応 |
| 8 | 郵便番号 | 文言置換「ー(長音)」→「-」 | Excelで手動対応 |
| 9 | 郵便番号 | 郵便番号が2個以上の場合、行を増やす | Seleniumで対応 |
| 10 | 郵便番号 | 大阪地裁・簡裁の取得時に、郵便番号・住所を分割 | Seleniumで対応 |
| 11 | 住所 | F,G列(住所1、住所2)追加 | Excel(数式)で対応 |
| 12 | 住所 | 住所とアクセス方法を分割 | Excel(数式)で対応 |
| 13 | 電話番号 | I~K列(窓口、番号、注意書き)追加 | Excel(数式)で対応 |
| 14 | 電話番号 | 電話番号と、それ以外の情報の分割 | Excel(数式)で対応 |
| 15 | 電話番号 | 電話番号が2個以上の場合、列を増やす | Seleniumで対応 |
1.Excelテンプレートの作成
まず、データ出力用のExcelシートを作成します。
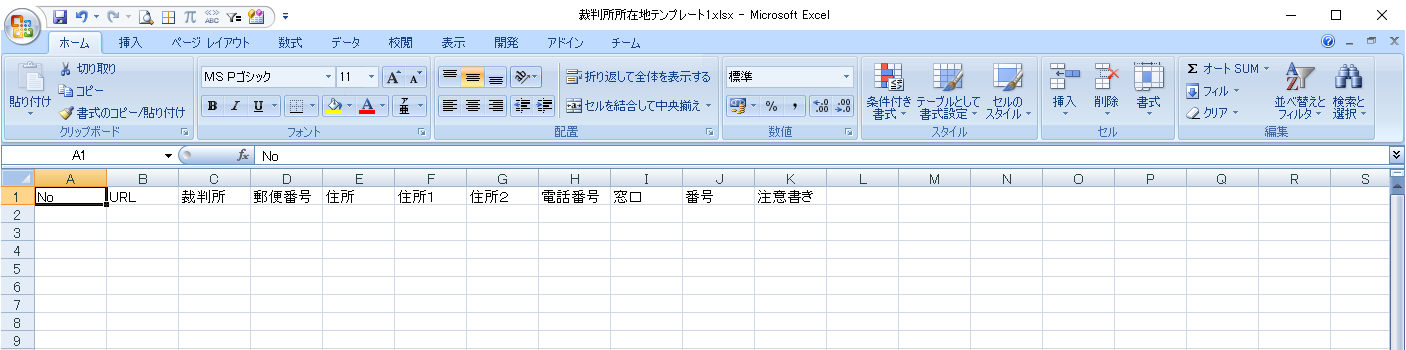
ヘッダー
シートのヘッダーは、裁判所名、郵便番号、住所、電話番号に、
- No3:A列にNo
- No4:B列にURL欄追加
- No11:住所1、住所2を追加
- No13:窓口、番号、注意書きを追加
となります。
Excel関数の入力
- No12:住所とアクセス方法を分割
- No14:電話番号と、それ以外の情報の分割
の関数式をセルに入力します。
住所とアクセス方法を分割
住所:不要データの分割で使用した数式をベースに、セルF2に以下の数式を入力します。
=IF(MIN(IFERROR(SEARCH("(",E2),999),IFERROR(SEARCH("(",E2),999),IFERROR(SEARCH(CHAR(10),E2),999))=999,E2,LEFT(E2,MIN(IFERROR(SEARCH("(",E2),999),IFERROR(SEARCH("(",E2),999),IFERROR(SEARCH(CHAR(10),E2),999))-1))セルG2に以下の数式を入力します。
=SUBSTITUTE(E2,F2,"")電話番号と、それ以外の情報の分割
電話番号:不要データの分割で使用した数式をベースに、セルI2に以下の数式を入力します。
=LEFT(H2,MAX(IFERROR(SEARCH(":",H2),0),IFERROR(SEARCH(":",H2),0)))セルJ2に以下の数式を入力します。
=IF(MIN(IFERROR(SEARCH("(",SUBSTITUTE(H2,I2,"")),999),IFERROR(SEARCH("(",SUBSTITUTE(H2,I2,"")),999),IFERROR(SEARCH(CHAR(10),SUBSTITUTE(H2,I2,"")),999))=999,SUBSTITUTE(H2,I2,""),LEFT(SUBSTITUTE(H2,I2,""),MIN(IFERROR(SEARCH("(",SUBSTITUTE(H2,I2,"")),999),IFERROR(SEARCH("(",SUBSTITUTE(H2,I2,"")),999),IFERROR(SEARCH(CHAR(10),SUBSTITUTE(H2,I2,"")),999))-1))セルK2に以下の数式を入力します。
=SUBSTITUTE(SUBSTITUTE(H2,I2,""),J2,"")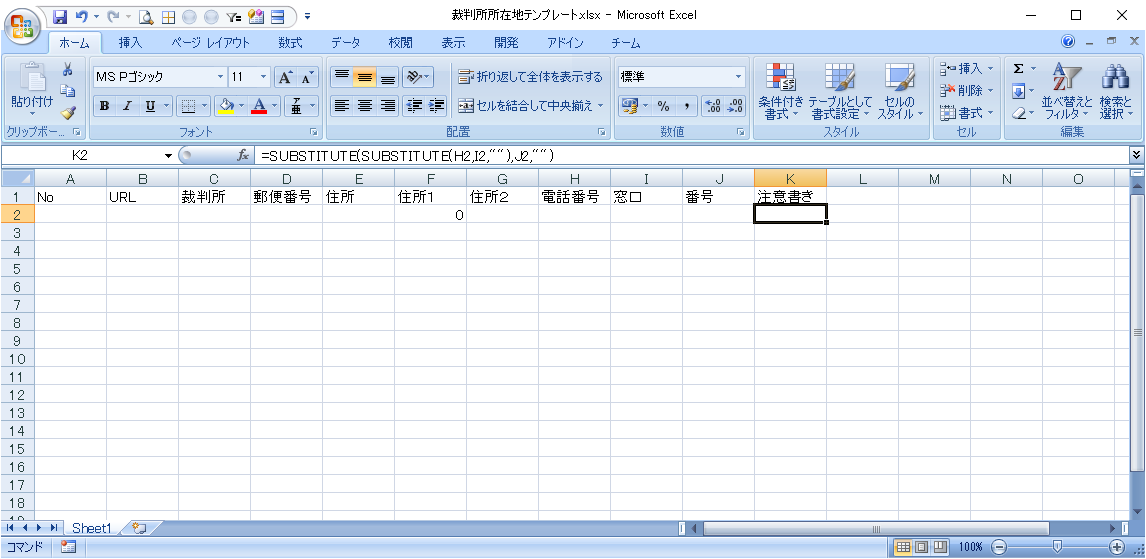
行コピー
これらの内容を各行にコピーします。
2.スクリプトの修正
元のスクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#列幅の設定
xw.Range('a:a').column_width = 25
xw.Range('b:b').column_width = 9
xw.Range('c:c').column_width = 50
xw.Range('d:d').column_width = 20
#ヘッダ出力
ws1.cells(1, 1).value = '裁判所'
ws1.cells(1, 2).value = '郵便番号'
ws1.cells(1, 3).value = '住所'
ws1.cells(1, 4).value = '電話番号'
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None #地域画面のリンク要素
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
#松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
#岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
before_handle = driver.current_window_handle # 現在のハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 1).value = 'エラー'
ws1.cells(k, 2).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
#通常ケース&松江
while link is not None:
#リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url)-4:] == '.pdf': #urlの末尾4文字が'.pdf'
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text
else:
before_handle = driver.current_window_handle # 現在のハンドルを保存
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 1).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 2).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
# while文の次の条件を設定
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
#Excel保存
wb1.save(book_path)
wb1.close()
Excelシートの変更を反映
新たなExcelシートに合うように、元のスクリプトを変更します。
ヘッダ出力を削除
ヘッダ情報は、あらかじめExcelシートに記入します。列幅も後で調整しますので、13~22行を削除します。
列順の変更を反映
列順は次のようになります。
| 項目 | 旧 | 新 |
| 裁判所名 | A列(1列目) | C列(3列目) |
| 郵便番号 | B列(2列目) | D列(4列目) |
| 住所 | C列(3列目) | E列(5列目) |
| 電話番号 | D列(4列目) | H列(8列目) |
上記スクリプトの網掛け部分を変更します。
Excelシートは既存のファイルを利用する
これまでは、Excelブックを新規で作成し、最後に保存していました。
元の処理
# Excelオープン
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1 = xw.Book()
ws1 = wb1.sheets[0]
#Excel保存
wb1.save(book_path)
wb1.close()これをテンプレートとなるファイルを開いて、別名で保存するように変更します。
修正内容
# Excelオープン
template_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
#Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
template_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None #地域画面のリンク要素
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
#松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
#岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
before_handle = driver.current_window_handle # 現在のハンドルを保存
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text
ws1.cells(k, 5).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text
ws1.cells(k, 8).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
ws1.cells(k, 3).value = 'エラー'
ws1.cells(k, 4).value = 'i=' + str(i)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
#通常ケース&松江
while link is not None:
#リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url)-4:] == '.pdf': #urlの末尾4文字が'.pdf'
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text
ws1.cells(k, 5).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text
ws1.cells(k, 8).value = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text
else:
before_handle = driver.current_window_handle # 現在のハンドルを保存
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
ws1.cells(k, 3).value = driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text
ws1.cells(k, 4).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
ws1.cells(k, 5).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
ws1.cells(k, 8).value = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
# while文の次の条件を設定
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
#Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()
Excel出力を関数化
後の修正でExcel出力部分を変更するのですが、今のスクリプトは色々な箇所で出力しているため、変更する箇所が多岐に渡ります。
今のうちに共通関数にして、Excel出力を1ヵ所にまとめておけば、変更がある場合も、修正は1か所で済みます。
Excel出力用の関数を作って、Excel出力する部分は、その関数を呼ぶように変更します。
Excel出力関数
def output(ws, row, col, str):
ws.cells(row, col).value = strws:ワークシート、row:行番号、col:列番号、str:出力内容
修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
def main():
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
template_path = \
r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
k=2 #Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
#表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None #地域画面のリンク要素
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
#松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
#岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text)
output(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text)
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
#知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
output(ws1, k, 3, 'エラー')
output(ws1, k, 4, 'i=' + str(i))
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
#通常ケース&松江
while link is not None:
#リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url)-4:] == '.pdf': #urlの末尾4文字が'.pdf'
output(ws1, k, 3, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text)
output(ws1, k, 4, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text)
else:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#Excel出力
try:
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text)
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text)
output(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text)
#電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
output(ws1, k, 8, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text)
#地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() #ブラウザの戻る
j += 1
k += 1
# while文の次の条件を設定
#通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
#Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()
#Excel出力関数
def output(ws, row, col, str):
ws.cells(row, col).value = str
#main関数
if __name__ == "__main__":
main()
あわせて主処理をmain関数にしています。
3.スクリプトの改良
上のスクリプトに、以下の対応を追加します。
- No4:B列に各裁判所ページのURLを出力
- No9:郵便番号が2個以上の場合、行を増やす
- No10:大阪地裁・簡裁の取得時に、郵便番号・住所を分割
- No15:電話番号が2個以上の場合、列を増やす
ページのURLを出力
B列(2列目)にページのURLを出力します。
表示しているページのURLは【driver.current_url】で取得できます。
詳細画面毎の処理で、Excelに出力している部分に以下のコードを加えます。
output(ws1, k, 2, driver.current_url)郵便番号が複数の場合、行を増やす
郵便番号(新フォーマットではD列)の内容が複数ある場合、行を追加します。
対象データ
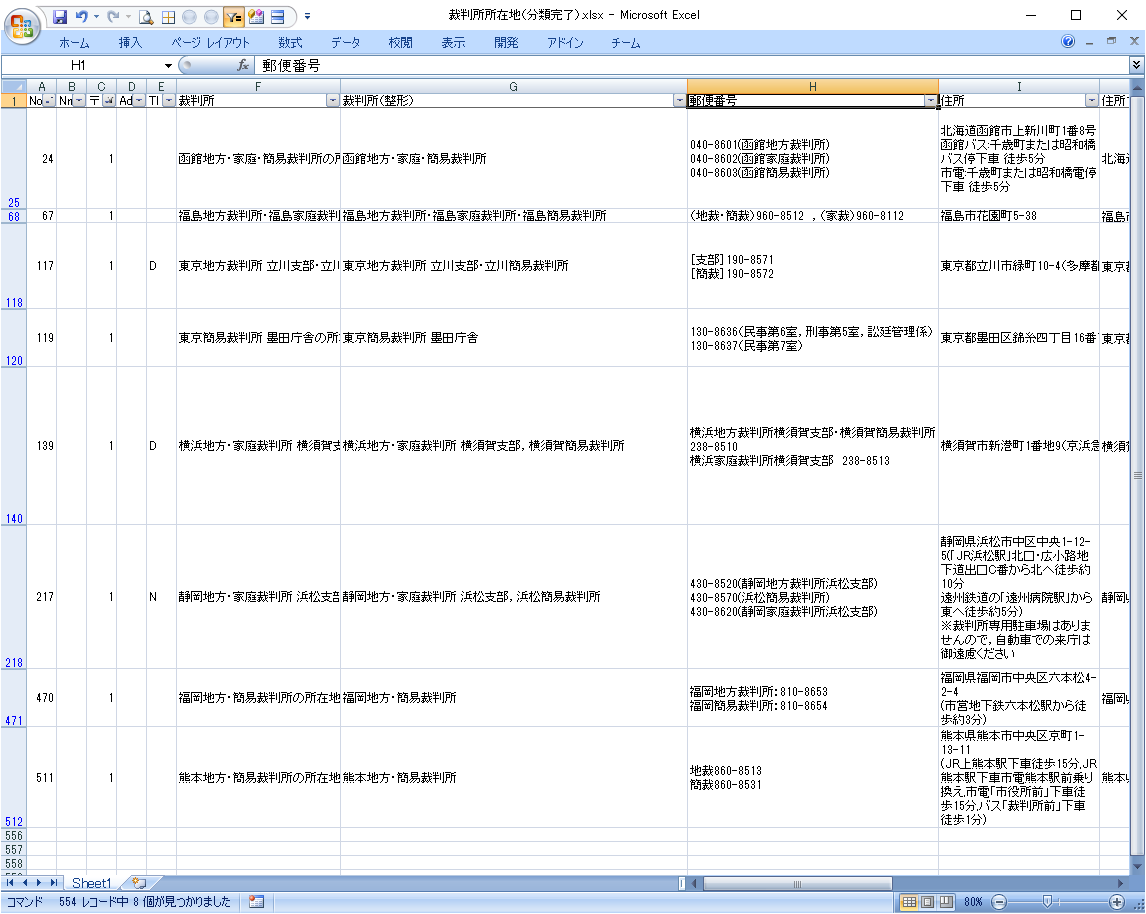
複数個の判定
2個以上あるかどうかの判定は、「福島地裁」は全角カンマ、それ以外は改行です。
しかし、改行で分割するデータの中にもカンマがあるので、
- 改行で分割できた場合、2個以上あると判定
- 1で分割できなかった場合で、全角カンマで分割できた場合、2個以上あると判定
というロジックになります。
#改行で分割して配列(list)に保存
l_out = str.splitlines()
#改行がない場合は「,(全角カンマ)」で分割
if len(l_out) == 1:
#配列の要素が1個の場合
l_out = str.split(',')
Excelシートに出力
次に郵便番号をExcelシートに出力します。
上で配列(list)に格納されている郵便番号の個数分、Excel出力します。
複数個出力する場合は、セルの行番号を増やします。
for i in range(len(l_out)):
ws.cells(行番号 + i, 列番号).value = l_out[i]
この処理を関数として実装します。
関数の戻り値は、郵便番号の個数(表示に必要な行数)とします。
郵便番号を出力する関数
def out_yubin(ws, row, col, str):
#改行で分割して配列(list)に保存
l_out = str.splitlines()
#改行がない場合は「,(全角カンマ)」で分割
if len(l_out) == 1:
l_out = str.split(',')
for i in range(len(l_out)):
ws.cells(row + i, col).value = l_out[i]
return len(l_out)
他の項目
郵便番号が2個以上で行が増えた場合、郵便番号以外の項目についても、増やす必要があります。
ただし、郵便番号以外の項目は、2行目以降も同じ内容を出力します。
よって、郵便番号の個数分だけ、同じ内容を出力することになります。
Excel出力関数を、繰り返し出力できるように修正します。
def output(ws, row, col, str, num):
#num:出力する行数
for i in range(num):
ws.cells(row + i, col).value = str
出力する行数(郵便番号の個数)は、郵便番号を出力する関数(out_yubin)の戻り値です。
行数のカウント
これまで1行ずつ増やしていたExcelの行数を、numだけ増やすように変更します。
修正前
k += 1修正後
k += num修正スクリプト
ここまでの内容をスクリプトに反映させます。
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
def main():
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
template_path = \
r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
k = 2 # Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
# 表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None # 地域画面のリンク要素
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
# 岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text)
output(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text, num)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text, num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# 知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
output(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, 'エラー', 1)
output(ws1, k, 4, 'i=' + str(i), 1)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
# 通常ケース&松江
while link is not None:
# リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url) - 4:] == '.pdf': # urlの末尾4文字が'.pdf'
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text)
output(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text, num)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text, num)
else:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text)
output(ws1, k, 2, driver.current_url, num)
# Excel出力
try:
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, num)
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
# 電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
output(ws1, k, 8, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text, num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# while文の次の条件を設定
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
# Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()
# Excel出力関数
def output(ws, row, col, str, num): #num:行数
for i in range(num):
ws.cells(row + i, col).value = str
#郵便番号出力
def out_yubin(ws, row, col, str):
#改行で分割して配列(list)に保存
l_out = str.splitlines()
#改行がない場合は「,(全角カンマ)」で分割
if len(l_out) == 1:
l_out = str.split(',')
for i in range(len(l_out)):
ws.cells(row + i, col).value = l_out[i]
return len(l_out)
# main関数
if __name__ == "__main__":
main()
最初に、郵便番号の個数を取得する必要がありますので、Excelに出力する順番を変更しています。
大阪地裁・簡裁の対応
対象画面


標準データでは郵便番号が記載されている一番目の欄に、郵便番号と住所が記載されています。
郵便番号と住所の取得
1段目から郵便番号と住所を分割して出力します。
#郵便番号と住所の取得
strbuf = driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
l_str = strbuf.splitlines()
#改行で分割
yubin = l_str[0][6:]
#「郵便番号:〒999-9999」から7文字目以降(数値部分)を取得
add = l_str[1][3:]
#「住所:XXXXXXXX」から4文字目以降(住所部分)を取得電話番号の取得
電話番号は2段目から編集します。
driver.find_element_by_xpath('//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text修正スクリプト
1段目に「住所:」という文言が含まれる場合、上記の処理を行います。
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
def main():
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
template_path = \
r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
k = 2 # Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
if i < 61:
continue
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
# 表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None # 地域画面のリンク要素
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
# 岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text)
output(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text, num)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text, num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# 知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
output(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, 'エラー', 1)
output(ws1, k, 4, 'i=' + str(i), 1)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
# 通常ケース&松江
while link is not None:
# リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url) - 4:] == '.pdf': # urlの末尾4文字が'.pdf'
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text)
output(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text, num)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text, num)
else:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#大阪地裁・簡裁
if '住所:' in driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text:
num = 1
output(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, 1)
#郵便番号欄に住所も含まれている
strbuf = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
l_str = strbuf.splitlines()
yubin = l_str[0][6:] #「郵便番号:〒」を削除
add = l_str[1][3:] #「住所:」を削除
output(ws1, k, 4, yubin, num)
output(ws1, k, 5, add, num)
output(ws1, k, 8, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
else:
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text)
output(ws1, k, 2, driver.current_url, num)
# Excel出力
try:
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, num)
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text, num)
output(ws1, k, 5, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
# 電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath( \
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
output(ws1, k, 8, driver.find_element_by_xpath( \
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text,num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# while文の次の条件を設定
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
# Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()
# Excel出力関数
def output(ws, row, col, str, num): #num:行数
for i in range(num):
ws.cells(row + i, col).value = str
#郵便番号出力
def out_yubin(ws, row, col, str):
#改行で分割して配列(list)に保存
l_out = str.splitlines()
#改行がない場合は「,(全角カンマ)」で分割
if len(l_out) == 1:
l_out = str.split(',')
for i in range(len(l_out)):
ws.cells(row + i, col).value = l_out[i]
return len(l_out)
# main関数
if __name__ == "__main__":
main()
電話番号が複数の場合、列を増やす
対象データ
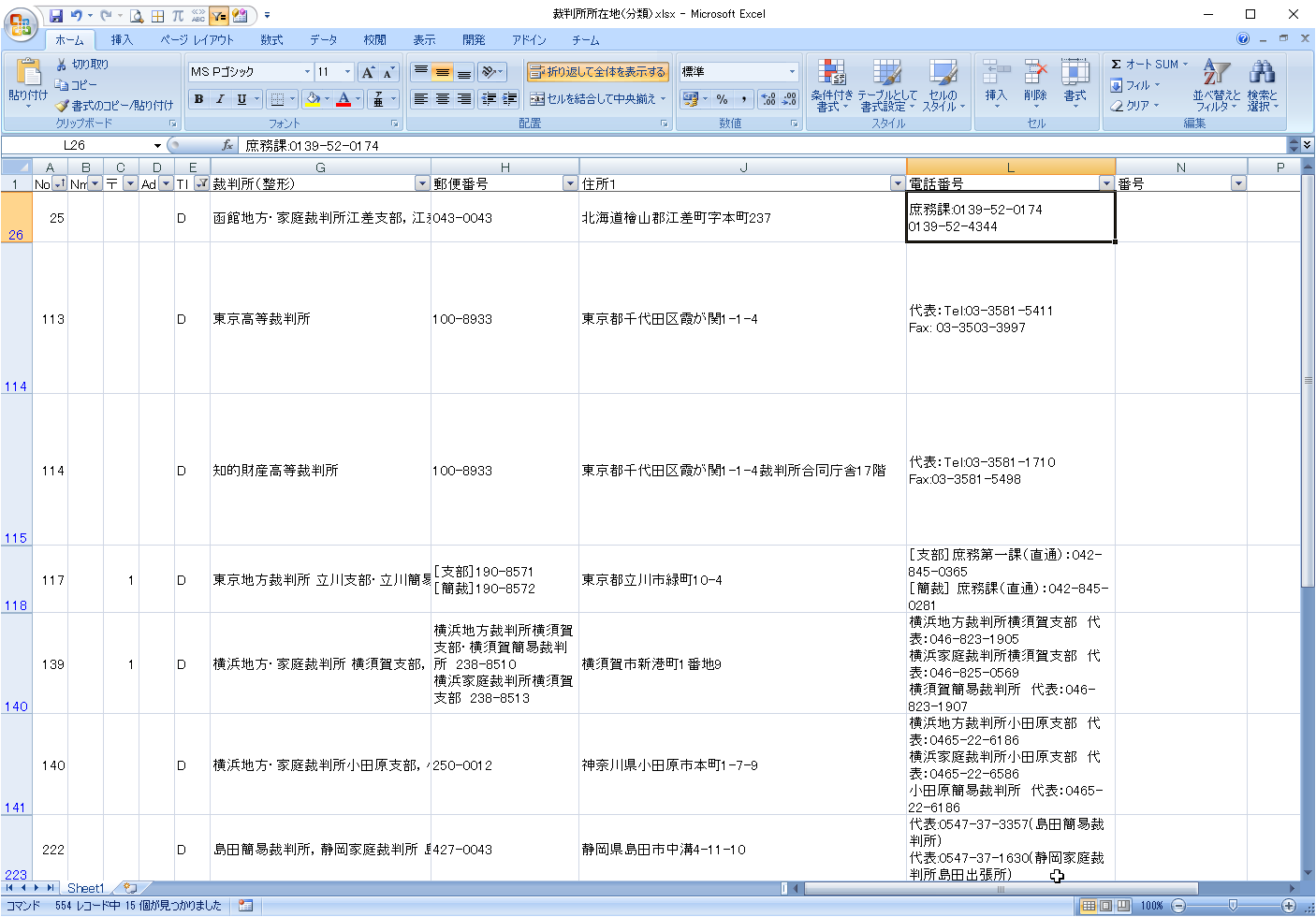
改行で電話番号の分割が可能です。
Excelテンプレート
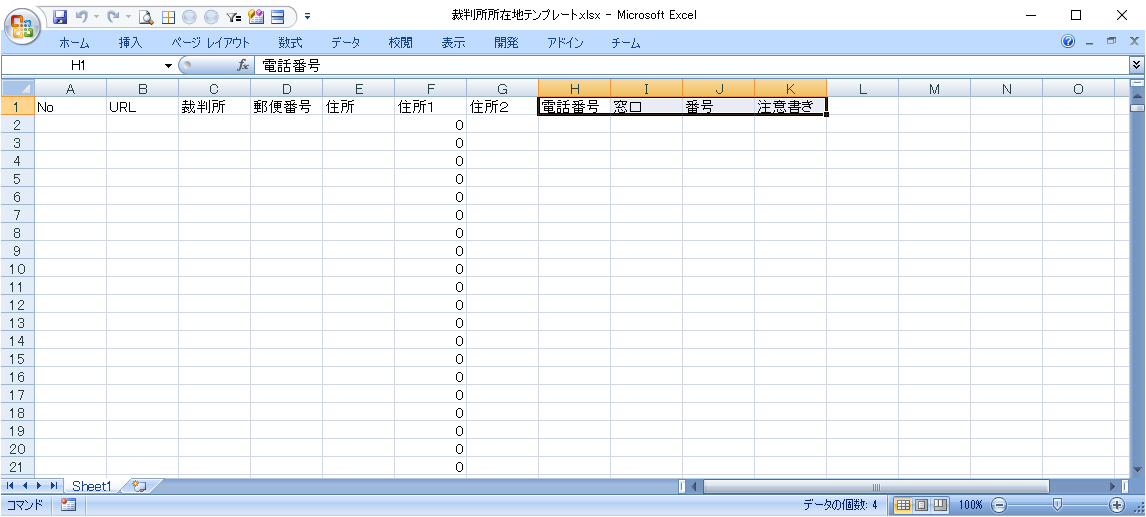
電話番号の件数に応じて、H列~K列の内容を右側に増やします。
対応内容
- 改行で分割できた場合、2件以上あると判定します。
- 複数個の場合は、L列に2件目の電話番号を出力します。
- セルI,J,K列を、セルM,N,O列にコピーします。
- 3件以上の場合は、2~3の処理を繰り返します。
郵便番号と同様に、電話番号を出力する関数を作成します。
電話番号を出力する関数
def out_tel(ws, row, col, str, num): #num:行数
#改行で分割して配列(list)に保存
l_out = str.splitlines()
for i in range(num):
for j in range(len(l_out)):
k = col + 4*j #出力列番号
ws.cells(row + i, k).value = l_out[j]
if j > 0:
if j == 1:
rng_copy = xw.Range(ws.cells(row + i, col + 1), ws.cells(row + i, col + 3))
rng_paste = xw.Range(ws.cells(row + i, k + 1), ws.cells(row + i, k + 3))
rng_copy.copy(rng_paste) #rng_copyをrng_pasteにセルのコピー
xlwingsのRangeオブジェクトを使用しています。
import xlwings as xw
Range領域 = xw.Range(開始セル, 終了セル)セルのコピーはRangeオブジェクトのcopyメソッドを使用しています。
コピー元.copy(コピー先)修正スクリプト
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
def main():
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
template_path = \
r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
k = 2 # Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
# 表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None # 地域画面のリンク要素
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
# 岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text)
output(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text, num)
out_tel(ws1, k, 8, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text, num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# 知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
output(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, 'エラー', 1)
output(ws1, k, 4, 'i=' + str(i), 1)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
# 通常ケース&松江
while link is not None:
# リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url) - 4:] == '.pdf': # urlの末尾4文字が'.pdf'
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text)
output(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text, num)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text, num)
else:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#大阪地裁・簡裁
if '住所:' in driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text:
num = 1
output(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, 1)
#郵便番号欄に住所も含まれている
strbuf = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
l_str = strbuf.splitlines()
yubin = l_str[0][6:] #「郵便番号:〒」を削除
add = l_str[1][3:] #「住所:」を削除
output(ws1, k, 4, yubin, num)
output(ws1, k, 5, add, num)
out_tel(ws1, k, 8, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
else:
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text)
output(ws1, k, 2, driver.current_url, num)
# Excel出力
try:
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, num)
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text, num)
output(ws1, k, 5, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
# 電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath( \
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
out_tel(ws1, k, 8, driver.find_element_by_xpath( \
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text,num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# while文の次の条件を設定
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
# Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()
# Excel出力関数
def output(ws, row, col, str, num): #num:行数
for i in range(num):
ws.cells(row + i, col).value = str
#郵便番号出力
def out_yubin(ws, row, col, str):
#改行で分割して配列(list)に保存
l_out = str.splitlines()
#改行がない場合は「,(全角カンマ)」で分割
if len(l_out) == 1:
l_out = str.split(',')
for i in range(len(l_out)):
ws.cells(row + i, col).value = l_out[i]
return len(l_out)
#電話番号出力
def out_tel(ws, row, col, str, num): #num:行数
#改行で分割して配列(list)に保存
l_out = str.splitlines()
for i in range(num):
for j in range(len(l_out)):
k = col + 4*j #出力列番号
ws.cells(row + i, k).value = l_out[j]
if j > 0:
if j == 1:
rng_copy = xw.Range(ws.cells(row + i, col + 1), \
ws.cells(row + i, col + 3))
rng_paste = xw.Range(ws.cells(row + i, k + 1), \
ws.cells(row + i, k + 3))
rng_copy.copy(rng_paste) #rng_copyをrng_pasteにコピー
# main関数
if __name__ == "__main__":
main()
スクリプトの実行
スクリプトを実行します。
結果の確認
結果を確認します。
ページのURLを出力

B列にページのURLが出力されています。
ただし、上の例ではURLが文字としてあるだけで、クリックしてもWebサイトにリンクしません。ハイパーリンクの設定をします。
郵便番号が複数件

「函館地方・家庭・簡易裁判所」の郵便番号が分割されて、3行で表示されています。
大阪地裁・簡裁
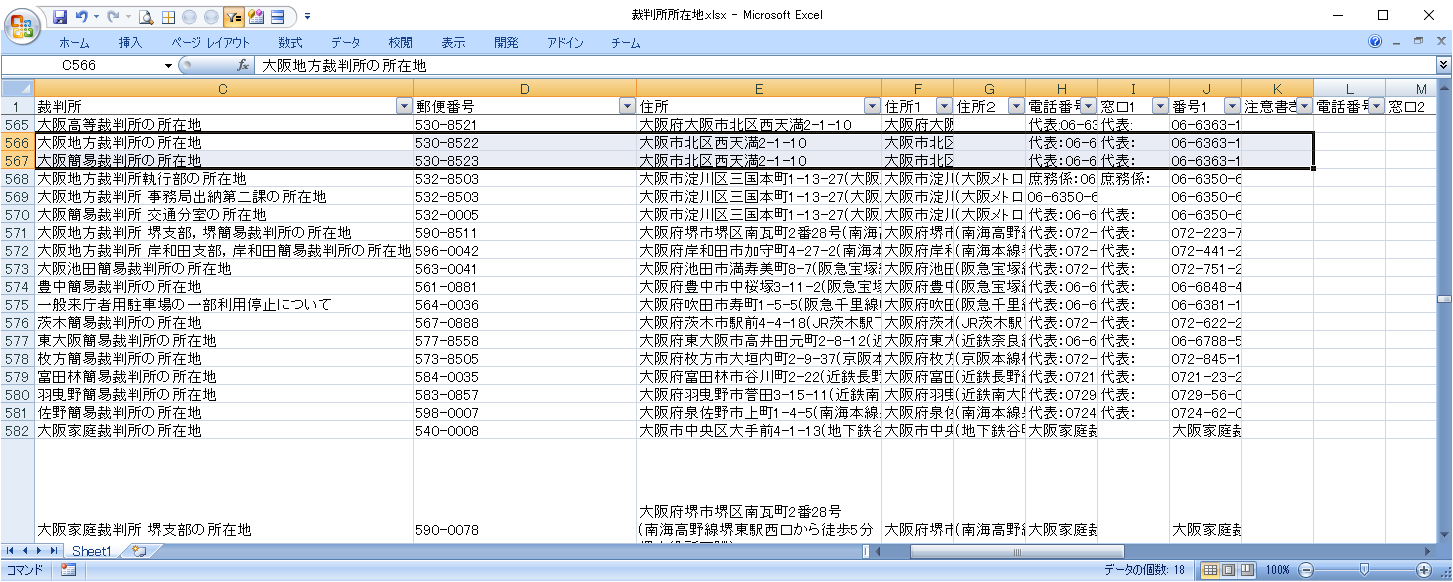
郵便番号、住所、電話番号が正しく編集されています。
電話番号が複数件

電話番号が分割されて、2件目以降も出力されています。
4.Excelシートの修正
エラーケース
電話番号の分割で、標準データのみを対象としたため、標準外データで上手く出力できていない箇所があります。
分割の例外
「PDF:99KB」のように、「:(コロン)」が含まれているため、電話番号が分割されてしまっています。
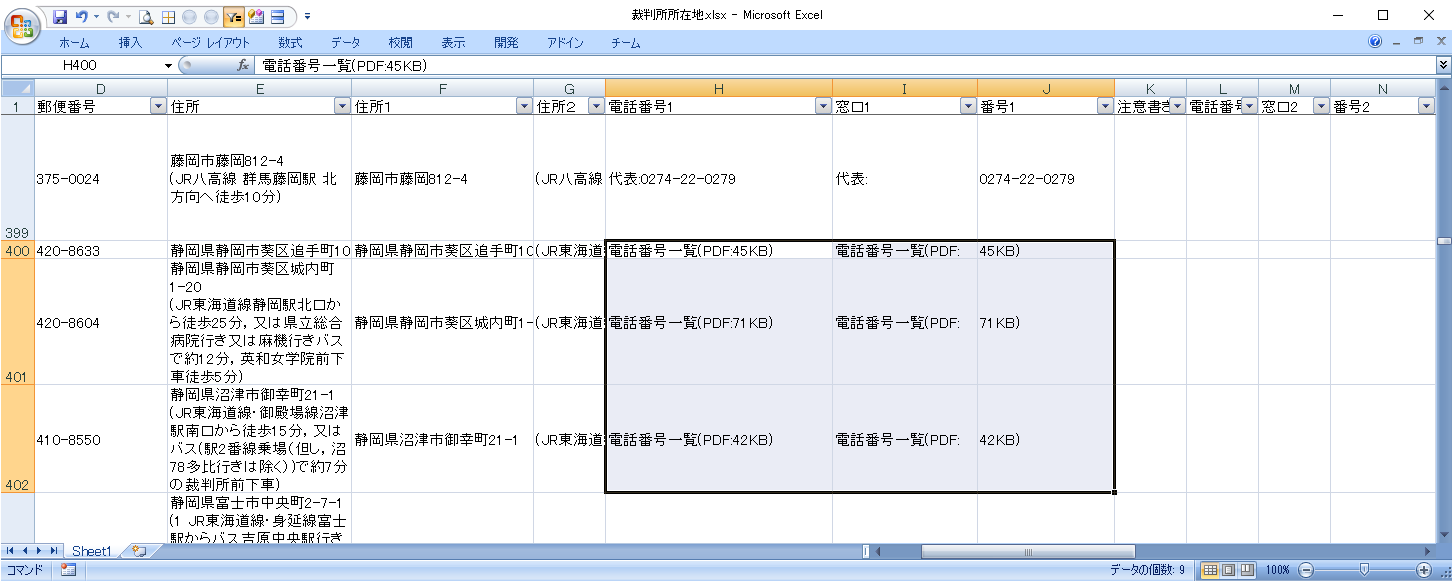
「PDF:」については、「:」を無視するようにします。
区切り文字の追加
電話番号が2件以上入っている場合は分割対象外にしていましたが、列を追加して出力するようにした結果、コロン以外の区切り文字が現れました。
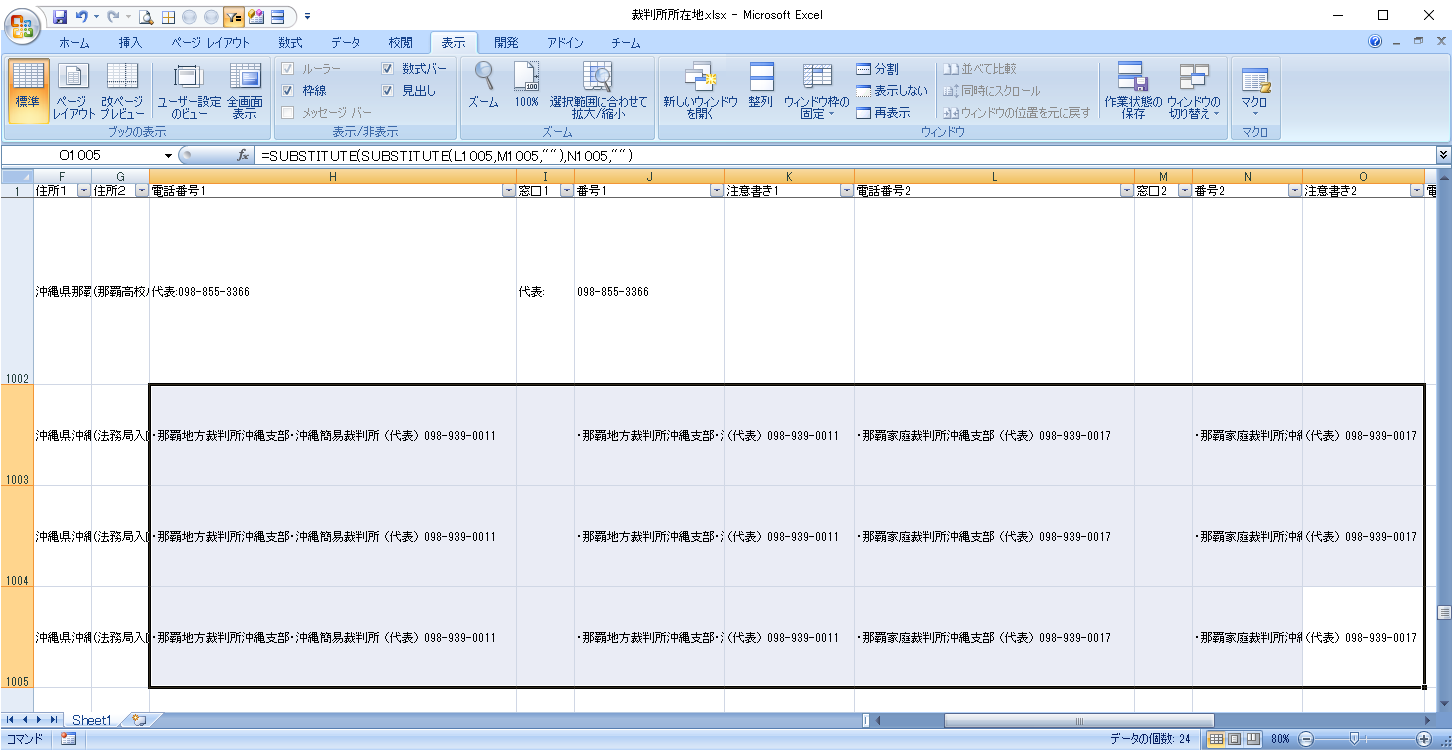
分割する区切り文字に「) (全角右かっこ+半角スペース)」を加えます。
区切り文字なし
電話番号が存在しないケースで、区切り文字がない場合、窓口(I列)ではなく、番号(J列)に出力されています。
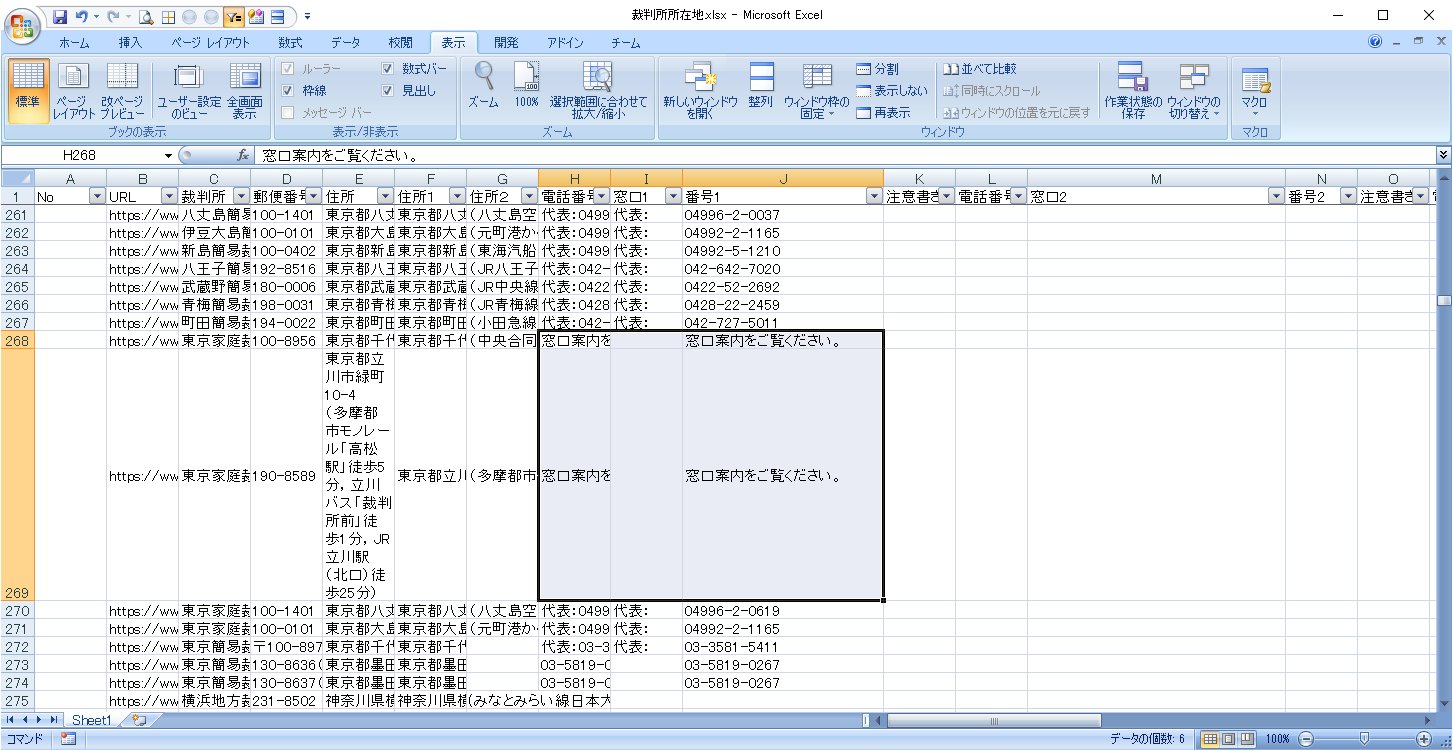
区切り文字がない場合は、I列にH列の内容をそのまま出力します。
ただし、以下のように、区切り文字がなく、電話番号が記載されている場合(数字で始まる場合)はI2は「""(空文字)」とします。
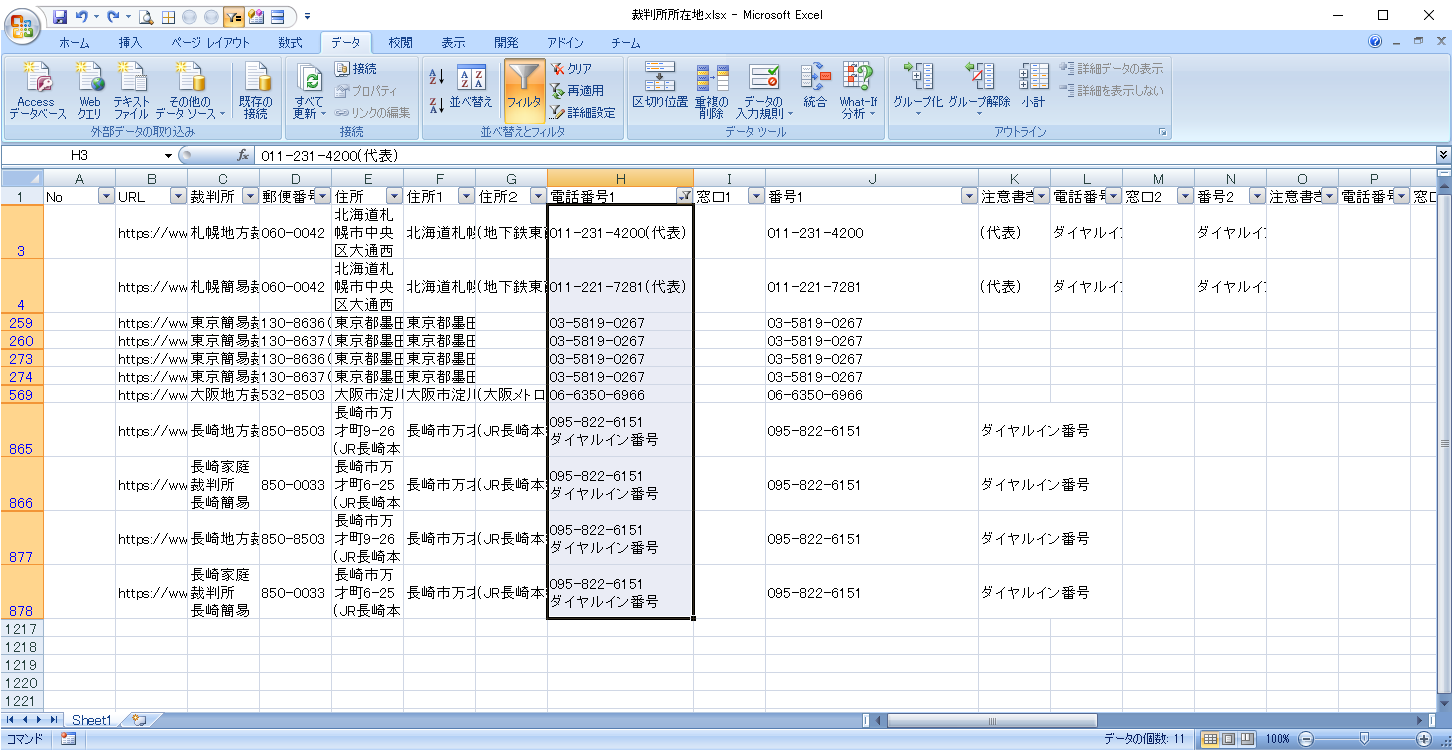
数式の修正
セルI2の数式を変更します。
元の数式
=LEFT(H2,MAX(IFERROR(SEARCH(":",H2),0),IFERROR(SEARCH(":",H2),0)))手順1
MAX関数内の【IFERROR(SEARCH(“:",H2),0)】【IFERROR(SEARCH(“:",H2),0)】は、電話番号(H2)に「:」「:」が含まれる場合の区切り位置を返しています。
今回、区切り文字に「) 」を追加したので、MAX関数内に【IFERROR(SEARCH(“) “,H2),0)】を追加します。
=LEFT(H2,MAX(IFERROR(SEARCH(":",H2),0),IFERROR(SEARCH(":",H2),0),IFERROR(SEARCH(") ",H2),0)))手順2
区切り文字がない(「:」「:」「) 」の検索結果が全てエラー)場合は、H列の内容をそのまま出力します。
=IF(AND(ISERR(SEARCH(":",H2)),ISERR(SEARCH(":",H2)),ISERR(SEARCH(") ",H2))),H2,LEFT(H2,MAX(IFERROR(SEARCH(":",H2),0),IFERROR(SEARCH(":",H2),0),IFERROR(SEARCH(") ",H2),0))))手順3
電話番号(H2)に「PDF:」が含まれる場合、「:」を無視します。
検索対象(H2)から、あらかじめ「:」を取り除くために、【SUBSTITUTE(H2,"PDF:","PDF*")】でH2の中身の「PDF:」を「PDF*」に置換します。
=IF(AND(ISERR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*"))),ISERR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*"))),ISERR(SEARCH(") ",SUBSTITUTE(H2,"PDF:","PDF*")))),H2,LEFT(SUBSTITUTE(H2,"PDF:","PDF*"),MAX(IFERROR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*")),0),IFERROR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*")),0),IFERROR(SEARCH(") ",SUBSTITUTE(H2,"PDF:","PDF*")),0))))手順4
最後に先頭が数字で始まる場合はH2の内容をそのまま表示します。
セルH2の先頭1文字が数字かどうかを【ISNUMBER(VALUE(LEFT(H2,1)))】で判定します。
VALUE関数でいったんLEFT(H2,1)の内容を数値に変換し、ISNUMBERで実際に数値かどうかを判定しています。
=IF(ISNUMBER(VALUE(LEFT(H2,1))),"",IF(AND(ISERR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*"))),ISERR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*"))),ISERR(SEARCH(") ",SUBSTITUTE(H2,"PDF:","PDF*")))),H2,LEFT(SUBSTITUTE(H2,"PDF:","PDF*"),MAX(IFERROR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*")),0),IFERROR(SEARCH(":",SUBSTITUTE(H2,"PDF:","PDF*")),0),IFERROR(SEARCH(") ",SUBSTITUTE(H2,"PDF:","PDF*")),0)))))この内容をExcelテンプレートに反映します。
5.完成スクリプト
ハイパーリンクの設定
URL欄(B列)をクリックすれば、該当ページにジャンプするように『ハイパーリンクの設定』をします。
スクリプトでURL出力時に、Excelの「HYPERLINK関数」を出力するようにします。
URLを出力する関数
def out_url(ws, row, col, str, num):
for i in range(num):
ws.cells(row + i, col).formula = '=HYPERLINK("' + str + '")'HYPERLINK関数の中の「"(ダブルクォーテーション)」は、Excelシート上で「=HYPERLINK(“https://~")」と、URLを囲む記号なので忘れないようにします。
完成スクリプト(最終版)
# -*- coding:utf-8 -*-
from selenium import webdriver
import xlwings as xw
def main():
# Chromeドライバ起動
driver_path = r'D:\SeleniumCodeChecker\driver\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
# Excelオープン
template_path = \
r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地テンプレート.xlsx'
wb1 = xw.Book(template_path)
ws1 = wb1.sheets[0]
k = 2 # Excelシートの行
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
count_i = len(driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]'))
for i in range(count_i):
driver.get('https://www.courts.go.jp/courthouse/map_tel/index.html')
driver.find_elements_by_xpath \
('//a[contains(text(),\'所在地・代表電話\')]')[i].click() #element(s)
# 表のヘッダーの相違でtrの序数が変わる
if len(driver.find_elements_by_xpath('//table/thead')) > 0:
j = 1
else:
j = 3
link = None # 地域画面のリンク要素
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
# 岡山
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
while len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']//a[1]')) > 0:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']//a[1]').click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
# 詳細画面も独自形式
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[1]/td').text)
out_url(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//caption').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[2]/td').text, num)
out_tel(ws1, k, 8, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div//tr[3]/td').text, num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# 知財高裁
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) == 0:
out_url(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, 'エラー', 1)
output(ws1, k, 4, 'i=' + str(i), 1)
k += 1
if len(driver.window_handles) > 1:
before_handle = driver.current_window_handle # ハンドルを保存
driver.switch_to.window(driver.window_handles[1])
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
# 通常ケース&松江
while link is not None:
# リンク先がpdfの場合は遷移無し
url = link.get_attribute('href')
if url[len(url) - 4:] == '.pdf': # urlの末尾4文字が'.pdf'
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[2]').text)
out_url(ws1, k, 2, driver.current_url, num)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a').text, num)
output(ws1, k, 5, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[3]').text, num)
output(ws1, k, 8, driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[5]').text, num)
else:
# 現在のハンドルを保存
before_handle = driver.current_window_handle
link.click()
# タブが2枚になっていたら、新規タブが開いているので、タブを切り替える
if len(driver.window_handles) > 1:
driver.switch_to.window(driver.window_handles[1])
#大阪地裁・簡裁
if '住所:' in driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text:
num = 1
out_url(ws1, k, 2, driver.current_url, 1)
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, 1)
#郵便番号欄に住所も含まれている
strbuf = driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text
l_str = strbuf.splitlines()
yubin = l_str[0][6:] #「郵便番号:〒」を削除
add = l_str[1][3:] #「住所:」を削除
output(ws1, k, 4, yubin, num)
output(ws1, k, 5, add, num)
out_tel(ws1, k, 8, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
else:
num = out_yubin(ws1, k, 4, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/dl[1]/dd').text)
out_url(ws1, k, 2, driver.current_url, num)
# Excel出力
try:
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-MainColum"]/div/h3').text, num)
except:
# 表上部の裁判所が存在しない場合はヘッダー部から編集
output(ws1, k, 3, driver.find_element_by_xpath \
('//div[@id="VcArea-Header"]/div/h2').text, num)
output(ws1, k, 5, driver.find_element_by_xpath (\
'//div[@id="VcArea-MainColum"]/div/dl[2]/dd').text, num)
# 電話番号が存在しないケースあり(横浜地方裁判所)
if len(driver.find_elements_by_xpath( \
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd')) > 0:
out_tel(ws1, k, 8, driver.find_element_by_xpath( \
'//div[@id="VcArea-MainColum"]/div/dl[3]/dd').text,num)
# 地域一覧画面に戻る
if len(driver.window_handles) > 1:
driver.close() # 新規タブを閉じる
driver.switch_to.window(before_handle) # 元のタブに戻す
else:
driver.back() # ブラウザの戻る
j += 1
k += num
# while文の次の条件を設定
# 通常ケース
if len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]/a')
# 松江
elif len(driver.find_elements_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')) > 0:
link = driver.find_element_by_xpath \
('//div//tr[' + str(j) + ']/td[1]//a')
else:
link = None
ws1.cells(k, 1).select() # 表示デモ用
# Excel保存
book_path = r'D:\SeleniumCodeChecker\ListCourt\裁判所所在地.xlsx'
wb1.save(book_path)
wb1.close()
# Excel出力関数
def output(ws, row, col, str, num): #num:行数
for i in range(num):
ws.cells(row + i, col).value = str
#郵便番号出力
def out_yubin(ws, row, col, str):
#改行で分割して配列(list)に保存
l_out = str.splitlines()
#改行がない場合は「,(全角カンマ)」で分割
if len(l_out) == 1:
l_out = str.split(',')
for i in range(len(l_out)):
ws.cells(row + i, col).value = l_out[i]
return len(l_out)
#電話番号出力
def out_tel(ws, row, col, str, num): #num:行数
#改行で分割して配列(list)に保存
l_out = str.splitlines()
for i in range(num):
for j in range(len(l_out)):
k = col + 4*j #出力列番号
ws.cells(row + i, k).value = l_out[j]
if j > 0:
if j == 1:
rng_copy = xw.Range(ws.cells(row + i, col + 1), \
ws.cells(row + i, col + 3))
rng_paste = xw.Range(ws.cells(row + i, k + 1), \
ws.cells(row + i, k + 3))
rng_copy.copy(rng_paste) #rng_copyをrng_pasteにコピー
#URL出力
def out_url(ws, row, col, str, num):
for i in range(num):
ws.cells(row + i, col).formula = '=HYPERLINK("' + str + '")'
# main関数
if __name__ == "__main__":
main()
スクリプトの実行
Excelテンプレート
修正したExcelテンプレートで、再びスクリプトを実行します。